4.1.4. 数据存储
了解tensor存储和拷贝机制对于优化内存使用和提升计算性能至关重要。通过掌握tensor 在内存中的布局和数据传输方式,开发者能够有效减少不必要的内存分配和数据拷贝操作,从而提升主机与设备间的通信效率和整体计算性能。
模型的输入和输出tensor可以存放在主机端CPU或后摩设备上。后摩设备内存由于硬件对齐要求,采用对齐填充,因此为非连续存储方式,其内存访问位置需要结合 stride(步幅)信息确定。而主机端存储则支持连续存储和非连续存储两种方式,提供更灵活的存储选项。
4.1.4.1. Stride
Stride与内存布局相关,描述了tensor在内存中的物理存储方式。具体来说,stride定义了内存中,从一个元素沿着某个维度移动到另一个元素时,要跳过的字节数(非元素数)。对于非图像数据,Stride[n] 数组的长度与tensor的维度数相同,每个元素 Stride[i] 表示在内存中沿第 i 个维度移动到下一个元素时,所需跳过的字节数。对于图像数据,stride的定义可参看 图像数据存储。
用户可以调用 TensorInfo::Stride(C++)或 tcim_lite.runtime.TensorInfo.stride(Python) 接口获取tensor的stride的值。
4.1.4.2. 连续存储
对于连续存储的tensor,stride与tensor的形状和存储顺序一致,用以确保内存中的元素按顺序排列。
一个N维tensor(N <= 6),第n维度的stride[n]计算公式如下:
![\mathrm{Stride}[n] = \prod_{i=0}^{n-1} \mathrm{Shape}[i]](../../_images/math/e1e8321480d99ba0779a9b7e0fcb6bba536579d8.png)
例如,一个形状为(3, 3)的int8类型的二维数组,如果存储方式是行主序(C-style),如果为连续存储,并且stride为(3, 1),则说明:
从一个元素移动到下一行同一列对应元素,需要跳过3个字节(stride[0] = 3)。
从一个元素移动到同一行的下一个元素,需要跳过1个字节(stride[1] = 1)。
如下图所示,示例中数据为连续存储没有空隙:
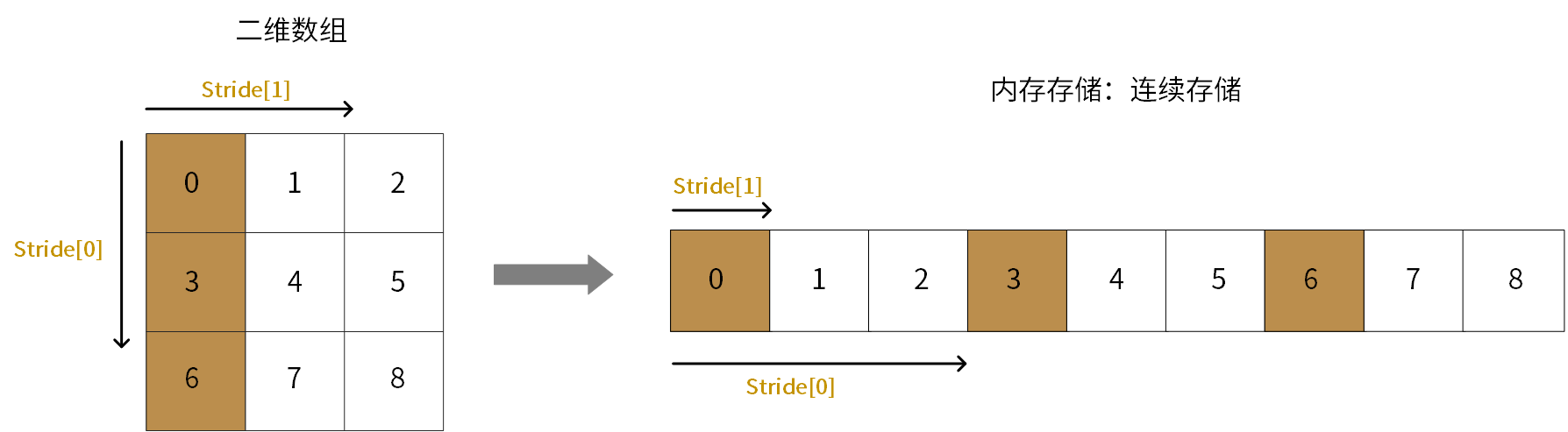
图 4.1 连续性存储
4.1.4.3. 非连续存储
对于非连续存储的tensor,stride与tensor的形状和存储顺序不再一致。此时,内存中元素之间的间隔可能并非按顺序排列,而是根据具体的访问模式和内存布局进行调整。因此计算stride时,公式不再遵循连续存储的规律:
![Stride[n] \neq \prod_{i=0}^{n-1} Shape[i]](../../_images/math/fe9a1d23b6fdd163c839dba45cfd50bd12512a89.png)
例如,对于一个形状为(3, 3)的int8类型的二维数组,如果存储方式是行主序(C-style),如果为非连续存储,并且stride为(5, 1),则说明:
从一个元素移动到下一行同一列对应元素,需要跳过5个字节(stride[0] = 5)。
从一个元素移动到同一行的下一个元素,需要跳过1个字节(stride[1] = 1)。
如下图所示,示例中数据存储存在无效填充(padding):
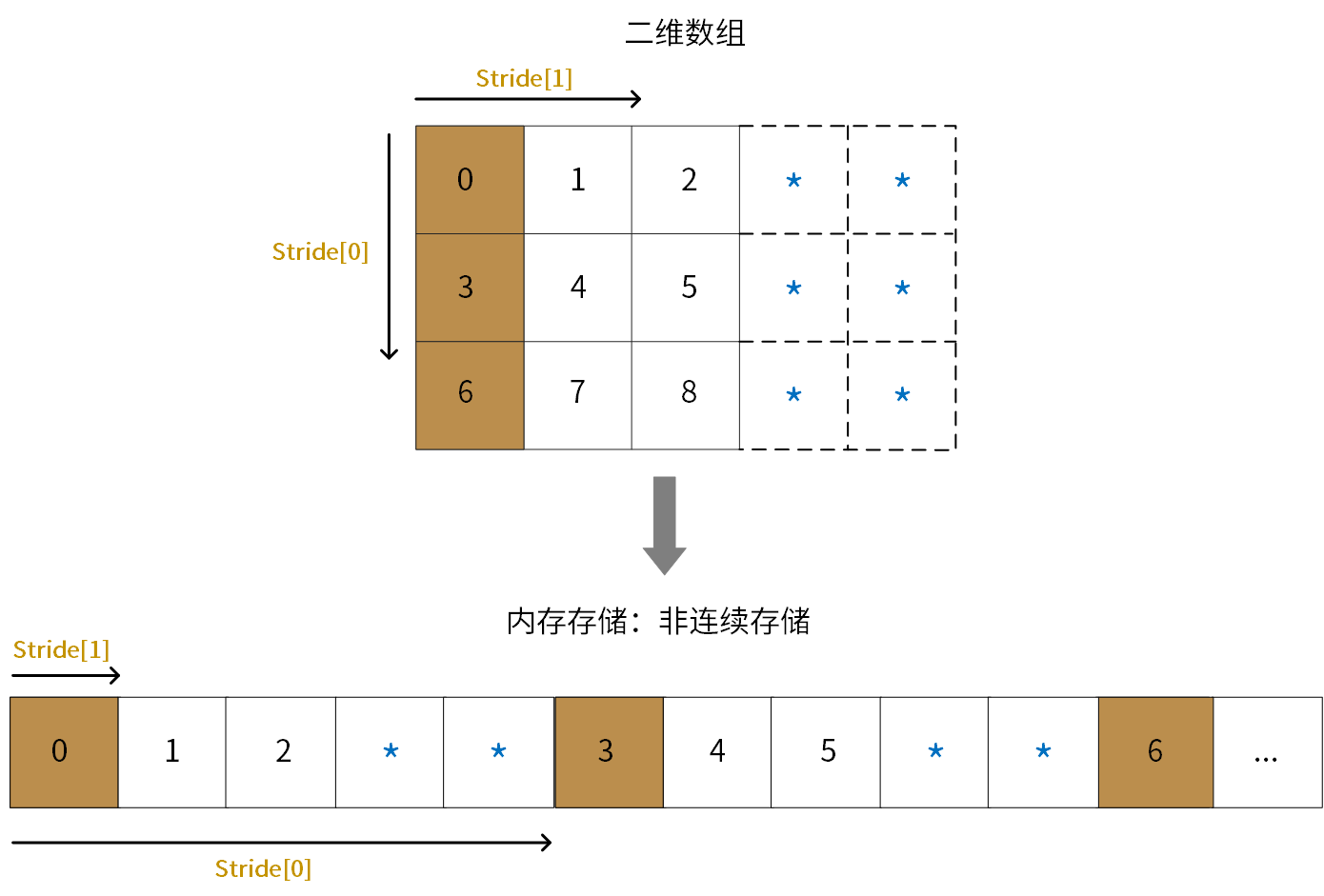
图 4.2 非连续性存储
4.1.4.4. 图像数据存储
在后摩设备上进行高效推理时,图像数据需要从原始存储结构转换为TCIM推理支持的存储格式。由于TCIM推理数据仅支持非图像数据格式,需将图像数据Y和UV分量拆分为两个独立的tensor(为非图像数据格式)进行存储。
用户调用 Module::SetInput(C++)或 tcim_lite.runtime.Module.set_input(Python)设置模型输入时,TCIM会自动将输入图像数据Y和UV分量拆分为两个独立的tensor,从而确保图像数据能够以 TCIM 推理框架支持的格式进行处理。此外,用户也可以显式调用 Tensor::SplitYUV(C++),将 YUV 数据手动分割为两个独立的非图像数据 tensor。
提示
为了简化操作并确保数据格式符合 TCIM 推理框架要求,建议用户使用 TCIM 自动处理图像数据的方式完成图像数据拆分。
TCIM支持的图像数据至少为三维,其形状为:
三维数据: [3, H, W],表示有三个分量(如 Y、U、V),高度为 H,宽度为 W。
四维数据: [N, 3, H, W],其中 N 表示批次大小。
更高维度: [D2, D1, D0, 3, H, W],其中-3维度表示颜色通道数,对应于 YUV 格式中的 Y、U、V 分量,该维度的值始终为3。
图像数据拆分后tensor形状为:
Y tensor的形状:
三维数据: [H, W]
四维数据: [N, H, W]
更高维度: [D2, D1, D0, H, W]
UV tensor的形状:
三维数据: [h, w, 2]
四维数据: [N, h, w, 2]
更高维度: [D2, D1, D0, h, w, 2]
其中,h 和 w 取决于 YUV 格式,例如:
YUV420SP: h = H / 2, w = W / 2
YUV422SP: h = H, w = W / 2
YUV444SP: h = H, w = W
4.1.4.4.1. 拆分后的存储格式
为了确保与后摩设备内存64字节对齐,stride定义了图像数据拆分后tensor在内存中各维度之间的字节间距,确保图像数据在内存中的正确对齐。
对于D维度的图像数据,它的stride长度为2D,Y tensor和UV tensor的stride计算方法如下:
Y tensor的stride:
Stride[0 ~ D-2]UV tensor的stride:
Stride[D-1 ~ 2D-2](因为 U 和 V 通道是交错存储,UV tensor通常包含比 Y tensor多一维。)Y tensor与UV tensor的首地址偏移:
Stride[2D-1]( Y tensor 和 UV tensor 起始地址之间的字节间距)
例如,batch为N,维度为4的图像数据,拆分后Y tensor和UV tensor首地址计算方法如下,其中
data 表示指向原始图像数据的起始位置的指针:
N batch的Y tensor首地址:
data[N * Stride[0]]N batch的UV tensor首地址:
data[N * Stride[3] + Stride[7]]Y和UV tensor内存大小:
memory_size = N * Stride[3] + Stride[7] = tensor_size + span_size其中:
memory_size表示存储该tensor所需的内存大小。可通过TensorInfo::MemSize(C++)或TensorInfo.mem_size(Python)接口获取。span_size表示对齐的填充字节数。连续存储时,span_size为0。可通过TensorInfo::SpanSize(C++)接口获取。
4.1.4.4.1.1. 示例
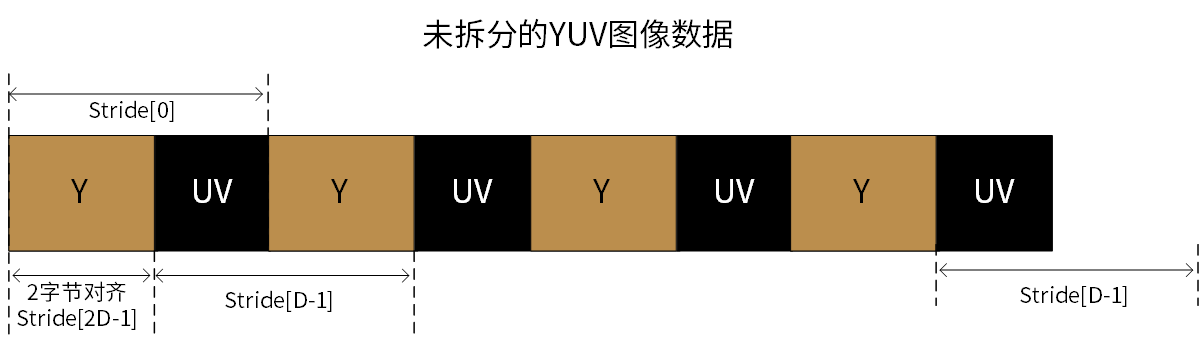
下图为未拆分的图像数据,在内存中连续存储的示例,其中Y、U 和 V 通道的数据按顺序存储:
下图为按照TCIM图像数据拆分要求,根据内存偏移量,拆分的两个Y和UV tensor:
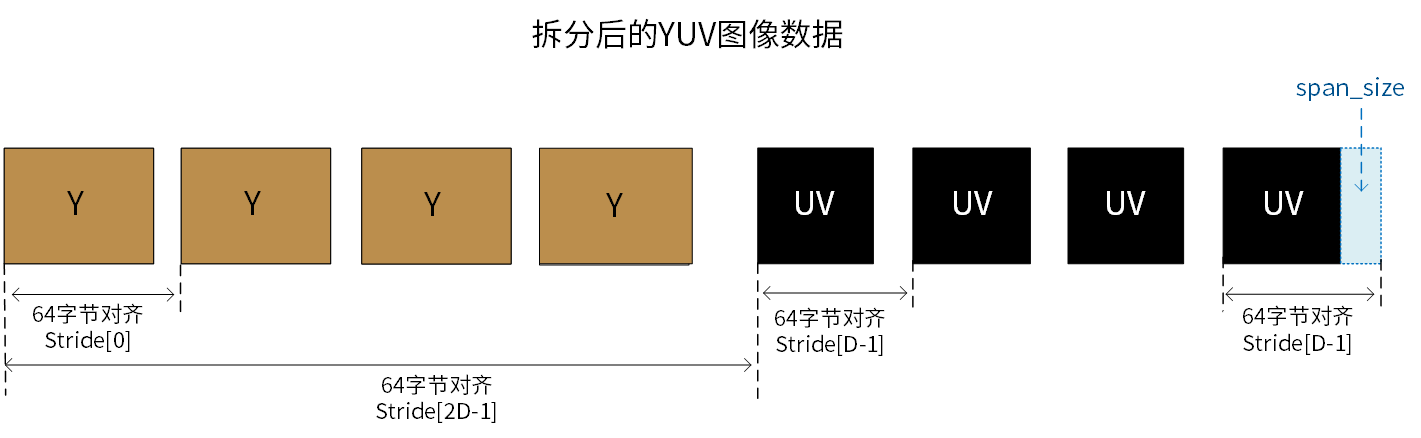
图 4.3 拆分后的图像数据示例
图中参数说明如下:
Stride[0]表示一个Y分量到下一个Y分量之间的字节数。Stride[D-1]表示一个UV分量到下一个UV分量之间的的字节数。Stride[2D-1]表示Y 分量的首地址与 UV 分量的首地址之间的偏移量。