5. 常见错误解析
5.1. 编译错误
模型编译失败并提示获取预留内存失败
模型编译过程中出现如下错误信息:
Failed to create a conext, err = -13 Register function from modules failed. fd 208, request 0xc020643, ret=-1, errno=718, Unknown error 718 Write bo fial, handl 1, xfer_size 152 hm800_client_write failedFail to get rsv mem_info. devid:0. ret=-13
原因:
未开启VT-d虚拟化技术。
解决方法:
启动主板VT-D虚拟化技术。
LLM模型编译失败并提示进程池异常退出
在LLM模型编译时,可能出现下面错误信息:
concurrent.futures.process.BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending.
原因:
该错误通常由系统内存耗尽(OOM,Out of Memory)引起。模型编译,尤其是LLM场景属于内存密集型任务。当编译器启动多个并行进程时,每个进程都会申请大量物理内存。若总内存需求超过了主机的物理内存容量,Linux内核的OOM Killer为保护系统稳定性,会强制终止占用资源最高的子进程,从而导致Python进程池崩溃。
在硬件配置较低的主机上,编译超大规模模型极易触发此问题。
解决方法:
故障确认。在报错后,通过查看内核日志确认是否触发了系统的内存保护机制:
dmesg | grep -i "oom-killer"
若输出中包含
Out of memory: Killed process字样,即可确定编译中断是由物理内存不足引发的。限制并行编译任务数。在
build_from_hmonnx模型编译接口中设置j参数为较小值,限制模型编译使用的CPU核数。通过减少投入编译的 CPU 核心数,可以直接减少并行的任务进程,从而显著降低总内存开销,确保编译在物理内存限值内完成。
模型编译MaxPool算子规格校验失败
模型编译时返回算子参数检查错误,导致编译中断:
error: fused["prelu_permute.pool", "/tmp/hmcc_tmp_brrx_er8.mlir":19:11]: 'hmir.pool2d' op stride should not be greater than kernel_size, but stride [2] > kernel_size [1] note: fused["prelu_permute.pool", "/tmp/hmcc_tmp_brrx_er8.mlir":19:11]: see current operation: %15 = "hmir.pool2d"(%14) <{ceil_mode = false, count_include_pad = false, dilation = array<i64: 1, 1>, kernel_size = array<i64: 1, 1>, padding_high = array<i64: 0, 0>, padding_low = array<i64: 0, 0>, pool_type = #hmir<pool max>, stride = array<i64: 2, 2>}> : (tensor<1x112x112x64xf16>) -> tensor<?x?x?x?xf16>, when parsing 'MaxPool' operator 'node_max_pool'.原因:
该错误是由于模型中名为node_max_pool的MaxPool算子参数触发了算子边界规格限制。
MaxPool算子的
kernel_size(即kernel_shape,内核大小)仅支持 [2, 2]、[3, 3]、[5, 5] 或 [7, 7]。当前模型设置的kernel_size为[1, 1] 属于不支持的规格。MaxPool算子的
stride值仅支持1 或 2。当前算子的stride设置为 [2, 2] 虽然支持,但由于kernel_size为 [1, 1],直接触发了编译器内部的算子规格校验规则:stride不能大于kernel_size(即 $stride [2] > kernel_size [1]$),导致校验失败。
解决方法:
调整模型参数规格为支持的算子规格。
算子约束详情,请参见 《软件平台快速入门》。
5.2. 推理错误
数据拷贝失败并提示 Bad address
在执行模型推理、数据拷贝或 Buffer 写入操作时,程序返回如下错误信息:
[HM_HAL][E][drm_ioctl][L:67]ioctl fd 3, request 0xc0206443, ret=-1, errno=14, Bad address [HM_HAL][E][hm800_write_bo][L:320]failed to write data to bo, error: 14, Bad address
其中,
errno=14对应Linux系统错误码EFAULT,表示传入内核接口的用户态地址无效。原因:
该问题通常是由于主机侧执行数据拷贝时,传入的源地址、目标地址或拷贝长度不合法,导致访问地址越界或访问到无效内存区域。
常见原因包括:
主机侧输入数据Buffer分配空间不足,实际拷贝长度超过Buffer可访问范围。
拷贝长度计算错误,例如未正确按照模型输入Shape、数据类型大小或 Batch 大小计算输入数据字节数。
传入的数据指针为空指针、野指针,或指向已经释放的内存。
多输入模型场景下,输入数据与模型输入节点不匹配,导致向错误的 Buffer 写入数据。
使用自定义预处理或后处理逻辑时,数据偏移地址计算错误,导致拷贝起始地址或结束地址越界。
解决方法:
请从以下几个方面排查并修正:
检查输入数据大小是否正确。
根据模型输入 Shape 和数据类型计算实际需要拷贝的数据大小,确认该大小不超过已分配的 Host Buffer 或设备 Buffer 大小。
例如:
输入数据大小 = N × C × H × W × sizeof(data_type)如果模型使用动态 Batch 或多 Batch 推理,还需要确认实际 Batch 大小与 Buffer 分配大小一致。
检查传入的地址是否合法。
确认数据拷贝接口中传入的 Host 侧地址有效,不能为:
空指针;
未初始化指针;
已释放内存地址;
超出数组或 Buffer 范围的地址。
检查拷贝长度是否超过Buffer范围。
确认写入 BO(Buffer Object)的数据长度不超过 BO 创建或分配时的大小。如果拷贝长度大于 BO 实际容量,需要修正 Buffer 分配大小或拷贝长度。
检查模型输入与数据绑定关系。
如果模型包含多个输入,请确认每个输入节点绑定的数据、Shape、数据类型和 Buffer 大小均与模型要求一致,避免将某个输入的数据错误写入另一个输入 Buffer。
检查自定义数据处理逻辑。
如果在拷贝前对输入数据进行了裁剪、拼接、偏移或格式转换,请重点检查偏移量、步长、对齐方式和数据长度计算是否正确。
SetInput失败并提示Tensor信息不一致
调用
SetInput设置模型输入tensor时,程序返回如下错误信息:[ERROR] /home/workspace/tcim_runtime_lite/src/tcim_module_impl.cc:138:SetDevTensor: 'info == local_info' FAILED! [ERROR] /home/workspace/tcim_runtime_lite/src/tcim_module_impl.cc:396:SetInput: 'input_container_->SetDevTensor(name, tensor)' FAILED!
原因:
SetInput会校验用户传入tensor的tensor信息是否与模型输入节点的tensor信息匹配。如果二者在形状、数据类型、内存布局、stride或连续性等信息上不一致,就会触发校验失败。常见原因包括:
创建tensor时未使用连续内存布局,导致tensor的stride或内存排布与模型输入要求不一致。
手动构造
tensor_info时,形状、数据类型或连续性等关键信息与模型输入tensor不一致。对tensor执行reshape、transpose、slice等操作后,tensor信息发生变化,不再满足模型输入tensor要求。
解决方法:
创建输入tensor时,建议直接从模型中获取对应输入节点的tensor信息,并根据模型输入要求创建tensor。对于需要连续内存布局的输入,可使用
AsContiguous()获取连续布局的tensor信息后再创建tensor。示例代码如下:
auto input_info = module.GetInputInfo(input_name).AsContiguous(); auto input_tensor = tcim::Tensor::CreateHostTensor(input_info); module.SetInput(input_name, input_tensor);
C++ 推理编译失败并提示 Tensor 默认构造函数不可用
使用C++推理时出现如下错误信息:
error: use of deleted function 'tcim::Tensor::Tensor()
原因:
由于
tcim::Tensor类没有默认构造函数,通过默认构造方式创建对象会引发此编译错误。同时也要避免隐式使用默认构造函数的操作,如避免通过[]操作符访问map等容器的元素。解决方法:
使用map的
insert和at等显式访问方法访问tensor。示例如下:注意
建议参照下面示例使用input_map.at("input.1"),不能使用input_map["input.1"]。ImageProc::I420To420sp((uint8_t *)input_map.at("input.1").Data(), (uint8_t *)img_yuv.data, size);推理失败并提示动态库加载失败
推理时出现如下错误信息:
Check failed: (lib_handle_ != nullptr) is false: Failed to load dynamic shared library tcim_resnet50.so tcim_resnet50.so: cannot open shared object file: No such file or directory
原因:
根据上面错误信息,TCIM找不到合适的
resnet50.hmm文件导致动态库路径/文件缺失或依赖库加载失败。解决方法:
需要确认二进制模型文件是否存在。
模型文件架构是否与目标机器匹配,如使用
readelf -h file_name查看模型文件架构是X86还是AArch64架构。
C++推理失败并提示module not exist
使用C++推理时返回
NOT_FOUND错误码,并返回以下错误信息:xxx error, module not exist
原因:
二进制模型文件未初始化。
解决方法:
初始化二进制模型文件。可通过以下任意方法初始化二进制模型文件:
通过静态方法
Module::LoadFromFile。示例如下:auto module = Module::LoadFromFile("tcim_resnet50.hmm");通过有参的构造函数
Module::Module,示例如下:Module("tcim_resnet50.hmm");使用默认构造函数,再调用
Module::LoadModel方法加载二进制模型文件,示例如下:Module module; module.LoadModel("tcim_resnet50.hmm");
示例中
resnet50.hmm为二进制模型文件名。API详情参看 《TCIM开发者手册》。
模型推理失败并提示 Cannot allocate memory
模型推理时,可能返回如下错误信息:
[2026-05-11 07:33:39 pid:46398 tid:46398] (33 hm_errcode)last error: Cannot allocate memory E/HMALLOCATOR [2026-05-11 07:33:39 pid:46398 tid:46398] (1064 xh2a_memory_allocator_alloc_buffer_object)fd 7 ioctl ALLOC size 0x10000000 failed
原因:
该错误通常表示设备侧内存不足,运行时无法为模型推理申请所需的 Buffer。
对于大语言模型,模型权重、运行时 Kernel、输入输出Tensor、KV Cache以及中间Buffer都会占用设备内存。当模型实际内存需求超过设备可用内存时,推理过程会返回
Cannot allocate memory错误。解决方法:
请按以下方式排查和处理:
使用模型信息获取工具查看模型内存占用。
模型信息获取工具当前支持在Linux 和 Windows环境中使用。可执行以下命令查看
.hmm模型文件的内存使用信息:readhmm --mem_usage gemma4-26b-a4b_prefill.hmm
返回示例如下:
"mem_usage": { "total": 36312843008, "kernel": 102964800, "weights": 14653841856, "inout": [ 1441792, 256, 256, 655360, 67108864, 268435456, 268435456, 268435456, 268435456, ... 536870912, 134217728, 524288 ], "workspace": [ 11469056 ] },工具使用详细说明,参看 《模型信息获取工具用户指南》。
确认模型总内存需求是否超过设备可用内存。
其中,
total表示模型运行所需的总内存规模,weights表示模型权重占用,kernel表示运行时 Kernel 占用,inout表示输入输出相关 Buffer 占用。如果
total接近或超过设备可用内存,模型可能无法正常加载或推理。检查当前设备内存占用情况。
如果设备上同时运行了其他模型或进程,可能导致可用内存不足。建议释放无关进程占用的设备资源后,重新运行推理任务。
根据内存需求选择处理方式。
如果确认模型内存需求超过设备可用内存,请根据实际业务场景选择以下方式处理:
优化模型运行参数
适当缩短上下文长度、降低 batch/query 数量,减少KV Cache、输入输出Buffer和中间Buffer的内存占用。
通过接口调用开启延迟分配策略
可通过调用TCIM API接口,开启延迟分配策略,降低模型加载或推理过程中的内存占用。该策略主要包括:
权重及加载阶段延迟策略:在模型加载时延迟分配和初始化主机端缓冲区,可降低加载阶段的峰值内存占用,适用于内存受限环境。可通过调用
tcim::Module::Option::EnableHostLazyLoading(C++ )或tcim_lite.runtime.Option.enable_host_lazy_loading(Python)接口设置。推理阶段 I/O 缓冲区延迟分配策略:在推理阶段按需分配输入输出缓冲区,避免未使用路径占用内存。可通过调用
tcim::Module::Option::EnableIOLazyMode(C++ )或tcim_lite.runtime.Option.enable_io_lazy_mode(Python)接口设置。
开启 LazyMode 后,首次访问相关缓冲区或模型加载过程可能产生额外开销。请根据实际业务场景重新验证模型功能和性能是否满足要求。
选择更大内存规格的硬件设备。
如果通过参数调整和 LazyMode 仍无法满足内存要求,请选择内存容量更大的硬件设备运行该模型。
RK3588 平台推理性能低于 x86_64 平台
在 RK3588 平台运行模型推理时,可能出现整体推理耗时高于 x86_64 平台的情况。
原因:
RK3588平台与x86_64平台在CPU调度策略、CPU 频率、大小核架构和 PCIe 链路规格等方面存在差异,可能导致Host侧数据传输耗时增加。
如果 perf log 中负责触发模型执行的
run接口耗时与 x86_64 平台接近,但负责设置输入数据的SetInput接口和负责获取输出结果的GetOutput接口耗时明显高于x86_64平台,通常说明性能差异主要来自Host侧数据准备、PCIe数据传输或输出回读阶段,而不是模型在设备侧的计算性能差异。解决方法:
请按以下方式排查和处理:
查看perf log,确认性能瓶颈位置。
对比RK3588平台与x86_64平台的
SetInput、run和GetOutput接口调用阶段的耗时:如果负责触发模型执行的
run接口耗时接近,说明模型在设备侧的计算性能基本一致。如果负责设置输入数据的
SetInput接口和负责获取输出结果的GetOutput接口耗时明显增加,说明主要瓶颈在Host侧数据准备、PCIe数据传输或输出回读阶段。
将CPU调整为性能模式。
查看当前CPU工作模式:
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
如果当前模式不是性能模式,可执行以下命令切换为性能模式:
echo performance > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
如需对所有CPU核生效,可根据系统CPU核数量,对各CPU节点分别设置。
设置线程亲和性,避免任务调度到小核。
RK3588 平台采用大小核架构,通常包含 4 个 Cortex-A76 大核和 4 个 Cortex-A55 小核。A55 小核的主频和处理能力低于 A76 大核,如果推理进程或数据传输相关线程被调度到小核运行,可能导致
SetInput和GetOutput阶段耗时增加。建议通过
sched_setaffinity将推理进程或关键数据传输线程绑定到A76大核运行。常见RK3588系统中,大核对应的CPU编号通常为4~7,实际编号请以目标系统为准。在单线程推理场景下,可设置环境变量
TCIM_XH2_USE_SYNC_MODE=1开启同步模式,使运行时直接在主线程中launch kernel,而不是额外启动子线程,从而减少主机操作系统线程创建、调度和上下文切换带来的开销。确认PCIe链路规格是否符合预期。
如果模型输入输出数据量较大,建议检查当前PCIe链路速率和链路宽度,确认是否达到RK3588平台支持的预期规格。
对于输入输出数据量较小的大模型推理场景,PCIe规格通常不是主要瓶颈;如果
SetInput和GetOutput耗时异常偏高,应优先排查CPU调频和大小核调度问题。
多线程推理失败并提示系统调用中断
在多线程推理场景下,模型推理可能失败,返回
Interrupted system call或Bad file descriptor等错误信息。原因:
当主机进入系统级睡眠或休眠状态时,后摩设备相关操作会受到影响。在多线程推理过程中,如果系统发生睡眠或从睡眠状态唤醒,推理相关的设备访问可能中断,从而导致推理失败。
解决方法:
请确保运行推理任务的主机关闭自动睡眠或休眠功能,避免在推理过程中进入睡眠状态。
Windows系统
在 设置 -> 系统 -> 电源和电池 -> 屏幕和睡眠 中,将 睡眠 相关选项设置为 从不,确保系统在推理过程中不会自动进入睡眠状态。
Linux系统
禁用系统休眠:
sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target恢复系统休眠:
sudo systemctl unmask sleep.target suspend.target hibernate.target hybrid-sleep.target查看当前状态:
systemctl status sleep.target suspend.target hibernate.target hybrid-sleep.target
Windows环境执行env.bat失败
Windows环境下,卸载原有 Python 并安装新版本 Python 后,运行 ModelZoo 模型库中提供的
env.bat失败。原因:
系统中
HOUMO_SDK_PATH环境变量配置不正确,导致脚本无法获取正确的运行时开发工具包路径。解决方法:
确认 Python 版本。确保系统已安装 Python 3.9 及以上版本。在命令行中执行:
python --version
确认 Python 解释器唯一。在命令行中执行:
where python
确认输出路径唯一;若存在多个路径,请确保排在最前的 Python 路径为期望使用的默认版本。
确认 Python 命令生效。
python命令可正常使用。py命令未生效或不作为默认 Python 入口。
检查
HOUMO_SDK_PATH环境变量。检查系统环境变量中是否存在HOUMO_SDK_PATH,并确保其值与当前驱动安装路径一致。如存在残留或错误配置,请删除该环境变量。重新执行
env.bat。
详细说明,参看运行时开发工具包中
houmo-examples-xh2\tools\win_envs\README.MD。
5.3. 运行时部署错误
Windows安装依赖失败并提示缺少MSVC编译工具
Windows 11 主机端安装Visual Studio C++时出现先错误:
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools"
原因:
该错误表明系统中缺少必要的 Microsoft C++ 编译工具链(MSVC)。
解决方法:
需要安装Microsoft Visual Studio C++ Build Tools 并确保相关组件已正确配置。
安装 Microsoft Visual Studio Build Tools。以管理员权限打开 PowerShell,执行以下命令安装 Visual Studio 2022 Build Tools:
winget install Microsoft.VisualStudio.2022.BuildTools
配置 C++ 开发组件。
启动 Visual Studio Installer。
在工作负载(Workloads)页面中,勾选 Desktop development with C++。
确保已选中以下关键组件:
MSVC v143 - VS 2022 C++ x64/x86生成工具
Windows 10/11 SDK
用于Windows的C++ CMake工具
测试工具核心功能 - 生成工具
C++ AddressSanitizer
vcpkg包管理器
点击 Install 或 Modify 完成安装。
示例如下图所示:
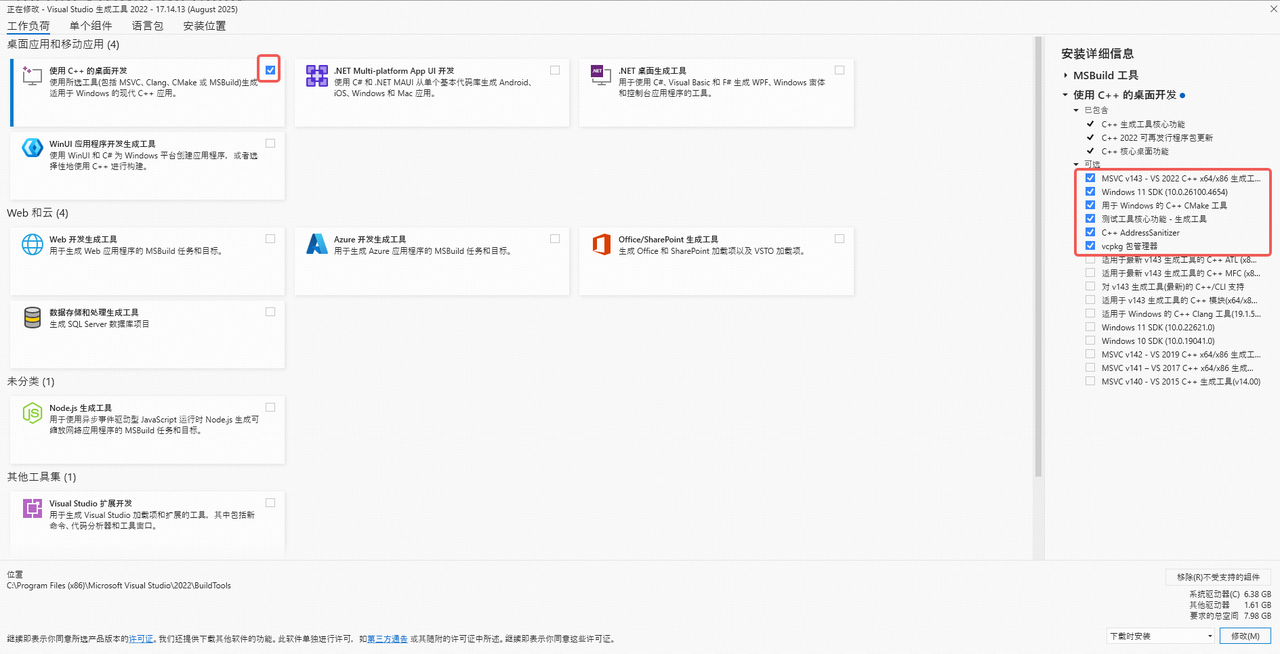
图 5.1 Microsoft Visual C++工作负载安装示例
openEuler安装运行时开发工具包失败并提示wheel构建失败
在openEuler 环境下安装运行时开发工具包时,可能返回下面错误信息:
ERROR: Failed building wheel for houmo-tcim-runtime-xh2 Failed to build houmo-tcim-runtime-xh2 ERROR: Could not build wheels for houmo-tcim-runtime-xh2, which is required to install pyproject.
解决方法:
安装G++编译器:
sudo yum install -y gcc-c++
验证G++是否可用:
g++ --version
Kylin安装运行时开发工具包失败并提示GLIBCXX版本不满足要求
在Kylin 环境下安装运行时开发工具包时,可能返回下面错误信息:
OSError: /usr/lib64/libstdc++.so.6: version 'GLIBCXX_3.4.26' not found
原因:
当前系统中的
libstdc++.so.6动态库版本过低,无法满足运行时开发工具包的 C++ 运行时依赖要求。解决方法:
预先加载高版本
libstdc++.so.6动态库。LD_PRELOAD=/path/to/libstdc++.so.6 tar -xzf houmo_tcim_runtime_<target_hw>_${distro}_$arch-<release>.tar.gz用户可执行以下命令检查动态库支持的 GLIBCXX 版本:
strings /path/to/libstdc++.so.6 | grep GLIBCXX_
5.4. 示例部署错误
Windows安装示例依赖失败并提示路径过长
在Winodws 11 主机端执行
pip install -r requirements.txt安装示例环境依赖时,如果返回下面错误信息:ERROR: Could not install packages due to an OSError: [WinError 206] The filename or extension is too long: "C:\\Users\\user\\AppData\\Local\\PythonSoftwareFoundationsoftwit1.Python.3.13_qbz5n2kfra8p0\\LocalCache\\local-packages\\Python313\\site-packages\\'onnx\'backend\'test\\data\'node\\'test_attention_3d_with_passt_and_present_qk_matmul_softcap_expanded\'test_data_set_0"
原因:
Windows 系统默认启用了传统的路径长度限制,单个文件的完整路径长度上限为 260 个字符。在安装 onnx 时,其源码包中包含部分命名较长的测试数据目录。当这些目录被解压到用户主目录下的 Python
site-packages路径中时,完整路径长度可能超过系统限制,从而触发WinError 206错误。解决方法:
通过启用 Windows 对 NTFS 长路径的支持来解除该限制:
同时按下 Windows 键 + R,输入 gpedit.msc,打开 组策略编辑器。
在左侧导航栏中依次选择:计算机配置 -> 管理模板 -> 系统 -> 文件系统 -> NTFS。
双击 启用NTFS长路径,将其设置为 已启用,点击 确定。
设置生效后无需重启系统,重新执行下面指令完成依赖安装:
pip install -r requirements.txt
5.5. 程序运行
Android 运行崩溃并提示 std::bad_cast
在Android环境下,程序运行过程中抛出如下异常并崩溃:
libc++abi: terminating due to uncaught exception of type std::bad_cast: std::bad_cast
原因:
该异常的根本原因在于同一进程空间内共存了两个ABI不兼容的 C++ 标准库(STL)实例,导致 C++ 运行时特性失效。
应用侧依赖:
libtcim_runtime_lite.so采用NDK编译,动态链接至NDK自带的libc++_shared.so。系统侧依赖:
libhal_xh2a.so作为系统组件,强制依赖Android系统内置的/system/lib64/libc++.so。
触发场景:
该问题通常发生在系统级应用或厂商预装应用中,应用层使用NDK编译,且配置为
APP_STL := c++_shared。系统层加载了依赖系统原生C++ 运行时的库,如libhal_xh2a.so。解决方法:
方法一:统一使用系统动态库 libc++.so
该方法强制NDK代码直接引用系统
libc++.so,不再将libc++_shared.so打包进APK。该方式确保全栈仅存在一个libc++.so实例,从根源消除冲突。方法二:创建软链接实现库重定向
该方法通过创建软链接
libc++_shared.so指向系统的libc++.so,强制诱导链接器加载系统原生STL实例,实现进程内STL唯一化。操作示例如下:在Android端,
houmo-tcim-runtime-xh2/lib目录下,执行下面指令:cp /system/lib64/libc++.so libc++_shared.so