2. 概述
2.1. 简介
后摩大道® M50 TCIM(Tensor Compiler In Memory,后摩神经网络模型编译器)是面向 后摩漫界® M50系列产品的推理加速引擎。基于开源MLIR(Multi-Level Intermediate Representation,多层次中间表示)框架,TCIM能够自动适配不同的后摩设备硬件平台,并通过多层次优化提升推理性能和资源利用率。TCIM提供C++和Python接口,支持运行时环境、端到端的模型优化和推理部署,使用户无需关注底层硬件细节,即可在不同场景下实现高效的推理部署。
2.2. 总体架构
TCIM编译器框架基于开源MLIR架构构建,架构如下图所示:
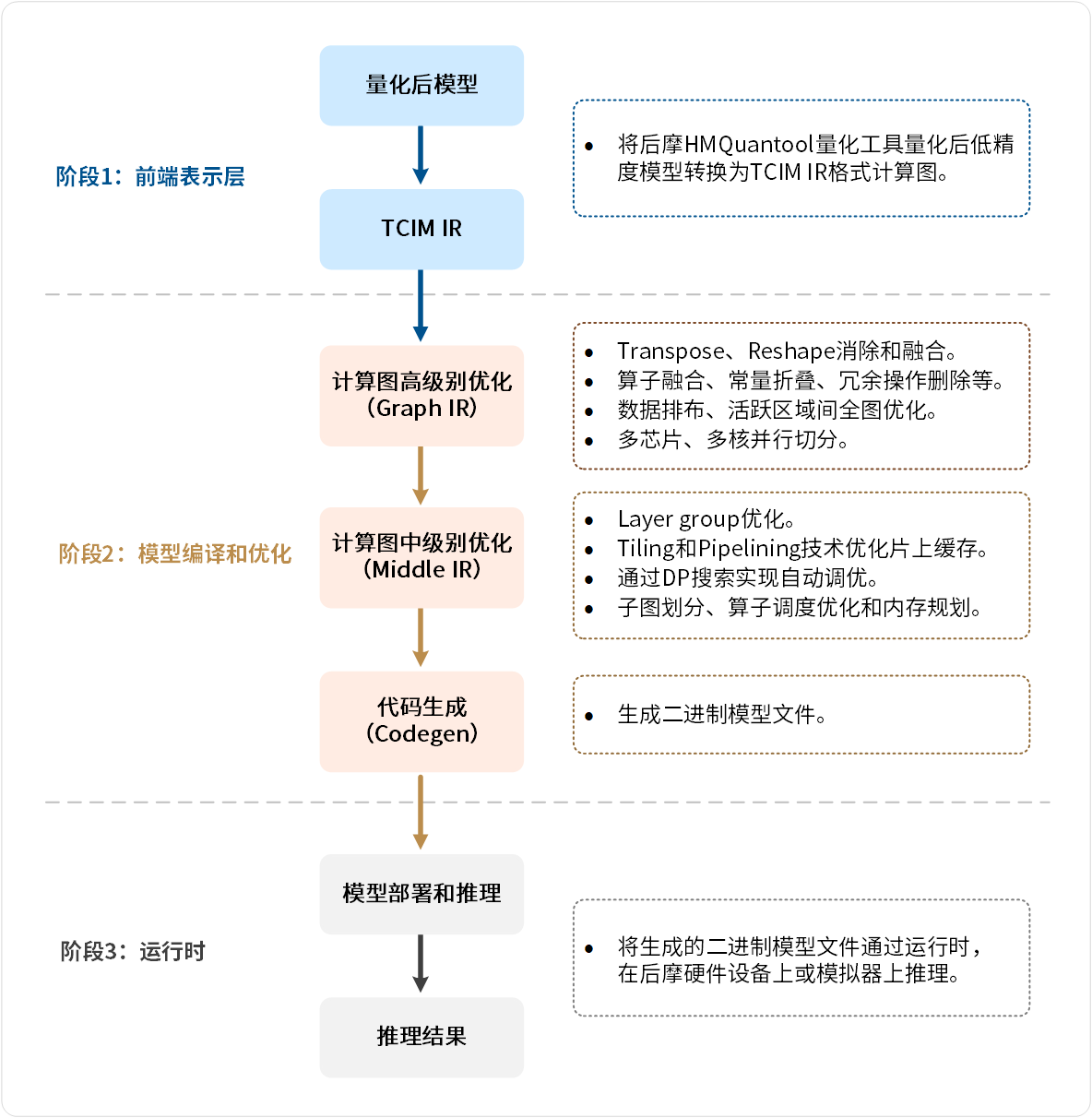
图 2.1 TCIM总体架构
TCIM总体架构主要包括以下三个层次:
2.2.1. 前端表示层
TCIM在MLIR架构的基础上,定义了专有的中间表示(IR),即TCIM IR,用于表示计算图。
前端表示层以量化后的混合精度模型作为输入,转换为TCIM IR格式的计算图,后续模型优化和代码生成都基于该计算图完成。
用户可通过后摩HMQuantool量化工具将浮点模型量化为低精度数据模型,作为该阶段的输入。
2.2.2. 模型编译和优化
该层主要包含计算图高级别优化、计算图中级别优化和代码生成三部分:
计算图高级别优化
主要完成对计算图的算法层和硬件层的优化。
算法层优化:包括Transpose和Reshape的消除和融合、算子融合、常量折叠、冗余操作删除等,以简化计算图结构、减少不必要的计算,从而提高算法执行效率。
硬件层优化:包括多芯片和多核并行切分、数据排布、活跃区间的全图优化等,以提升硬件资源利用效率,确保模型充分发挥硬件性能。
计算图中级别优化
主要完成计算优化、数据存储和访问优化,以及计算图结构优化。通过算子调度优化、内存优化和自动化搜索等技术,生成优化后的算子时序图。
数据存储及访问的优化:通过Layer group优化减少访存量,使用Tiling和Pipelining技术提高片上缓存的利用效率,同时进行算子调度的优化和内存规划,以提升硬件资源的使用效率和计算性能。
计算优化:通过DP(Dynamic Programming,动态规划)搜索实现自动调优,提升性能效率。
计算图结构优化:包括子图划分等,以减少冗余操作和提高执行效率,从而提升整体性能。
代码生成
将计算图转换为二进制模型文件。采用内存中代码生成(In Memory Codegen),提高模型编译速度。生成的二进制模型文件包含了优化后的计算图,确保推理执行高效,并充分利用硬件资源。
2.2.3. 运行时
运行时(Runtime)提供了模型部署和推理的接口以及运行环境。生成的二进制模型文件可在后摩设备上执行推理并输出结果,或者在模拟器上运行并生成模拟推理结果。
2.3. 主要功能
TCIM支持主要功能如下:
支持主流算子和多维张量计算: 支持CNN和Transformer等模型中常用算子,支持最多6维张量计算。
强大且灵活的模型编译功能:
支持通过Python接口将量化后的 ONNX 模型编译为高效二进制模型文件(.hmm或.hmms),用于在后摩设备上部署和运行。
支持在1个、2个或4个IPU核上进行张量并行计算。
支持 O0 ~ O2 编译优化级别,灵活调整编译优化策略以满足不同需求。
轻松部署至后摩设备: 支持通过 Python 或 C++ 接口将编译后的二进制模型文件部署到后摩设备上。
智能性能分析与可视化: 支持记录和导出模型运行信息,并提供可视化展示功能,帮助用户分析和优化推理性能。
可靠的精度: 通过高效的优化和计算图调整,确保性能的同时维持高度精确的推理结果,保证模型输出的准确性和稳定性。
极致的性能优化: 通过多层次的计算图优化和并行计算等技术,最大发挥硬件性能,显著提升推理速度和效率。
最小化内存占用: 通过优化张量内存分配和管理,减少内存占用,提升系统效能。
简洁易用的接口: 提供直观且高效的Python和C++接口,使开发者能够快速完成从模型编译到推理部署的全过程。
2.4. 优化特性
TCIM支持多种编译时和运行时优化手段,帮助用户在后摩设备上以最小的内存占用实现最高性能的推理。TCIM提供的主要优化包括:
计算图优化: 通过算子融合、常量折叠、冗余分支删除、公共子表达式消除等技术进行计算图优化,有效提升推理效率。
张量排布优化: 通过全局分析和优化张量排布,提升内存访问效率和数据处理性能。
子图划分与流水并行: 支持在模型中划分子图并采用流水并行策略,从而减少内存访问量,提升计算效率。
张量内存分配优化: 通过优化张量内存分配,减少空间占用,提升资源利用率。
2.5. 适用场景
TCIM适用于但不限于以下推理业务场景:
图像、视频处理
大语言模型
图像生成
2.6. 编程流程
TCIM开发主要流程如下图所示:
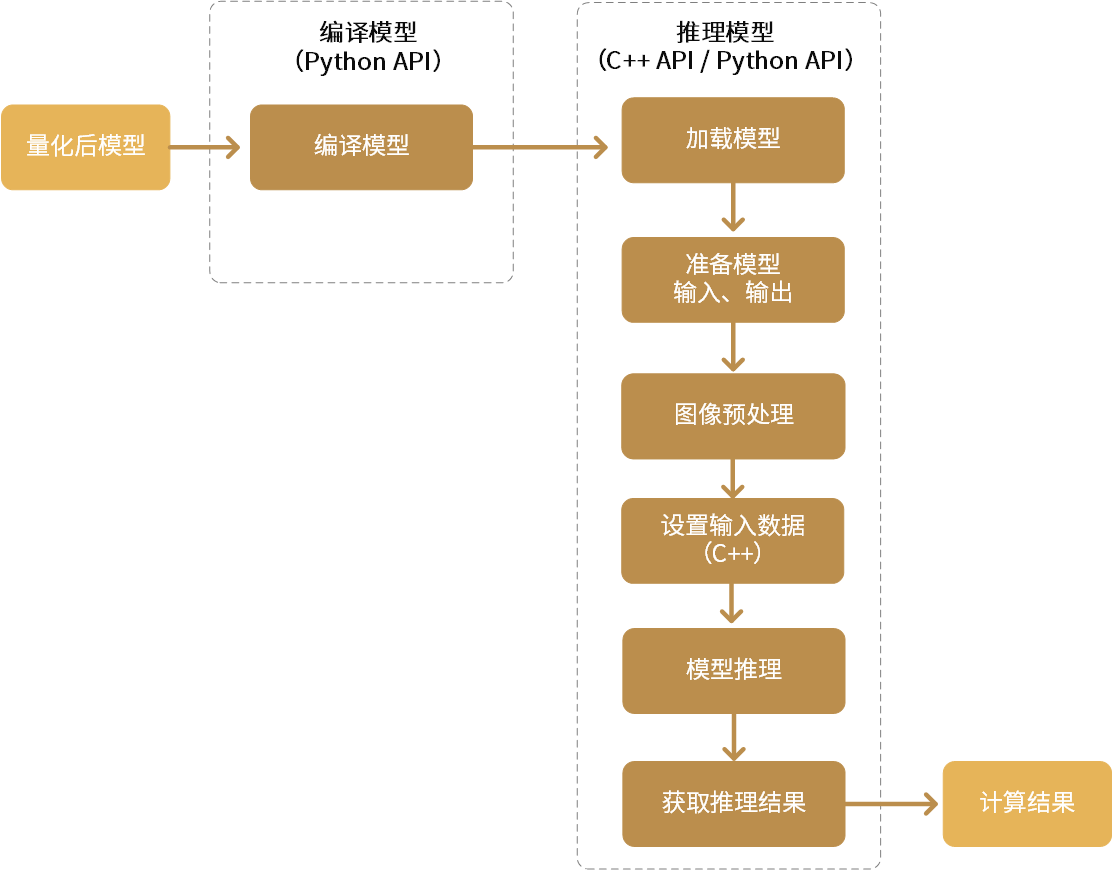
图 2.2 TCIM开发主要流程
TCIM将HMQuantool量化工具量化后的网络模型作为输入,完成模型编译和推理。有关量化工具详细说明,参看 《HMQuantool量化工具用户手册》。
用户需调用TCIM Python API编译模型,然后再通过TCIM Python API或 C++ API完成模型推理,最终输出推理结果。