4.4. 模型部署
后摩支持单个模型部署到后摩设备上。详情如下表所示:
模型数量\设备数量 |
单个后摩设备 |
多个后摩设备 |
|---|---|---|
单模型 |
支持。 详情参看 单模型单设备部署。 |
支持。 详情参看 单模型多设备部署。 |
多模型 |
支持。 详情参看 多模型部署。 |
支持。 详情参看 多模型部署。 |
4.4.1. 单模型单设备部署
单个模型支持部署在单个后摩设备上。模型编译是将量化后的网络模型编译成可以在后摩设备上运行的二进制模型文件,再在后摩设备上完成模型推理。代码示例和主要操作步骤,参看 单模型单设备样例。
部署流程如下图所示:
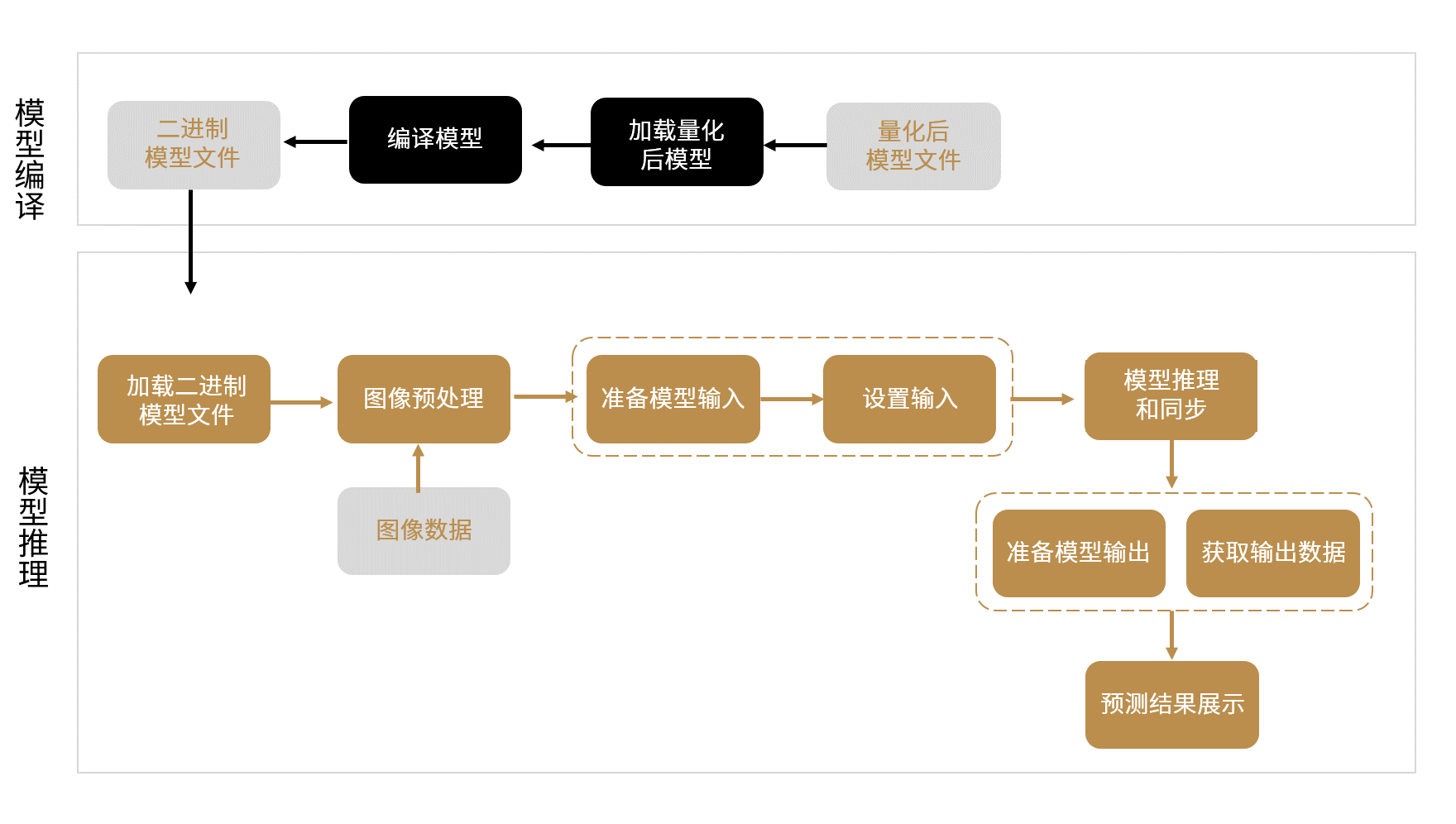
图 4.15 单模型单设备编译和推理流程
4.4.3. 单模型多设备部署
单个模型可以同时部署在多个后摩逻辑设备上。每颗 M50芯片都会映射为一个带有唯一ID的逻辑设备,用户在模型部署和推理时通过后摩设备逻辑ID 选择设备。当 M50产品包含多颗芯片时,可以利用多个逻辑设备实现模型的并行部署和推理。
与单模型单设备部署相比,多设备部署在代码使用上主要有以下区别:
模型编译设置:
调用
build_from_hmonnx接口时,需通过ndevice指定参与推理的逻辑设备数量。模型编译后生成二进制模型文件格式为.hmms。模型部署前初始化:
在创建
Weight Manager前,必须先通过DevManager指定要使用的后摩逻辑设备 ID 及后端类型,示例如下:dev_manager = tcim.runtime.DevManager([1,0], "Xh2HalBackend") weight_manager = tcim.runtime.WeightManager(dev_manager)
示例中,模型将部署在逻辑设备 1 和逻辑设备 0 上。
除以上差异外,其余推理流程与单模型单设备部署保持一致。
4.4.4. 多模型部署
多模型支持部署在单个后摩设备或同一台主机的多个后摩设备上。模型编译在主机端完成,与单模型编译方式相同。模型推理支持对多个模型进行推理或对单个模型进行多次推理,可通过多线程多stream方式实现。多线程在执行推理过程中,会争夺计算资源来完成各自的任务,因此每个线程推理次数不确定。
推理流程如下图所示:
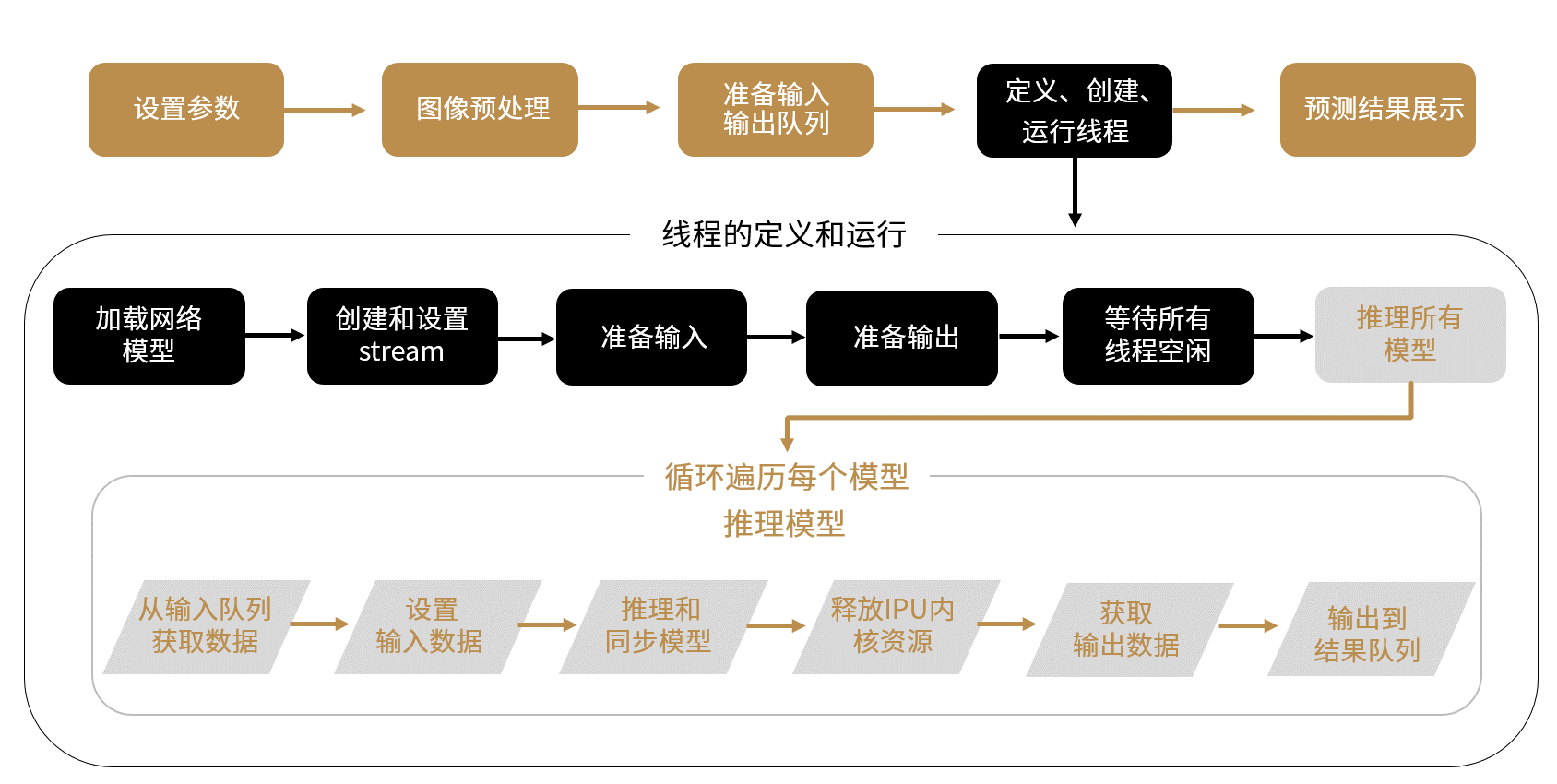
图 4.16 多模型推理流程
4.4.4.1. 限制说明
支持多个后摩设备部署,但目前仅在4个后摩设备上做了验证。