4.1.5. 数据获取及拷贝
TCIM提供接口支持各种场景下的tensor的获取及拷贝,如下图所示:
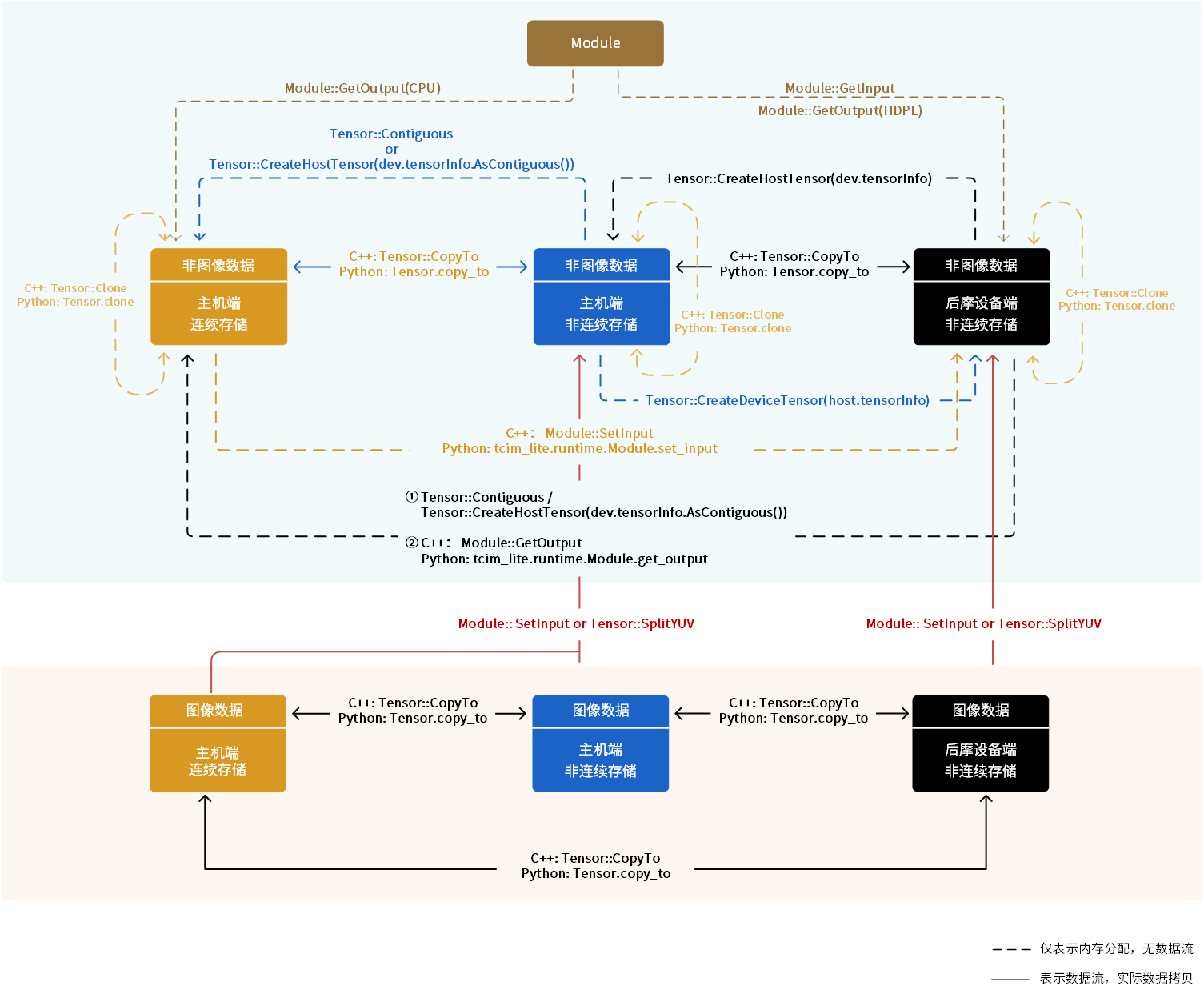
图 4.4 Tensor获取及拷贝接口调用关系
根据上图所示,TCIM支持从模型直接获取输入输出tensor、分配同布局的独立tensor以及主机端与设备端之间的tensor拷贝:
从模型中直接获取输入输出Tensor
输入tensor:调用
Module::GetDevInput(C++)或tcim_lite.runtime.Module.get_dev_input(Python)。输出tensor:调用
Module::GetOutput(C++)或tcim_lite.runtime.Module.get_output(Python)。
分配同布局的独立 Tensor
用户可通过 Tensor::Clone(C++)或 tcim_lite.runtime.Tensor.clone(Python)接口,克隆当前 Tensor 对象。该接口会为新 Tensor 对象分配与原 Tensor 对象相同内存布局的独立内存,并将原始 Tensor 对象的数据复制到新分配的内存中。此外,新的 Tensor 对象与原 Tensor 对象具有相同的tensor信息。如果需要将数据拷贝到新分配的内存中,可调用 Tensor::CopyTo(C++)或 tcim_lite.runtime.Tensor.copy_to(Python)。
图像数据拷贝
图像数据可调用 Tensor::CopyTo(C++)或 tcim_lite.runtime.Tensor.copy_to(Python)在主机端连续存储内存、主机端非连续存储内存以及后摩设备端内存之间拷贝。但由于TCIM推理对数据格式的要求,TCIM内部会将图像数据 Y 和 UV 分量拆分为两个独立的tensor 进行存储。详情参看 图像数据存储。
主机端与后摩设备端间的Tensor拷贝
TCIM模型推理是在后摩设备上完成的,因此在推理前,输入输出tensor必须存放到后摩设备上。如果模型输入输出tensor保存在主机端,则需将tensor拷贝到后摩设备上。如果是多模型推理,模型间可以共享存放在设备端的输入输出tensor,则无需将tensor拷贝到主机端后再拷贝回后摩设备上,从而减少了不必要的数据拷贝。
下面详细介绍如何在主机端与后摩设备端间拷贝Tensor。
4.1.5.1. 主机端到设备端拷贝
从主机端拷贝输入输出tensor到后摩设备端,可调用下面接口:
Tensor::CopyTo(C++)或tcim_lite.runtime.Tensor.copy_to(Python):直接拷贝数据到后摩设备。该接口会根据内存特性自动调整数据存储方式。目前仅支持主机端非连续存储到后摩设备端拷贝,如果将主机端连续内存数据拷贝到后摩设备端,需要先拷贝到主机端非连续的缓存后才能拷贝到后摩设备端。Module::SetInput(C++) 或tcim_lite.runtime.Module.set_input(Python):设置模型输入数据时,TCIM 会自动将数据转换为后摩设备内存格式,并拷贝到预分配的后摩设备内存上。
4.1.5.1.1. 高性能方法
用户可通过下面方法最大化内存使用效率,并加速数据拷贝:
将tensor存放在主机端非连续存储内存中。根据
TensorInfo::Stride(C++)或tcim_lite.runtime.TensorInfo.stride(Python) 获取tensor的stride信息,并根据该stride信息,在主机端存放 tensor,以确保与设备端的内存布局一致。调用
Tensor::CreateDeviceTensor为该 tensor 在后摩设备上分配内存。调用
Tensor::CopyTo将tensor数据拷贝到后摩设备上。
在此过程中,用户必须自行通过stride信息手动跳转访问数据。相比于直接调用 Tensor::CopyTo(C++)或 tcim_lite.runtime.Tensor.copy_to(Python)拷贝数据,该方法已完成数据访问的跳转,因此无需额外内存布局调整。
4.1.5.2. 设备端到主机端拷贝
从后摩设备端拷贝输入输出tensor到主机端,可调用下面接口:
Tensor::CopyTo(C++)或tcim_lite.runtime.Tensor.copy_to(Python)直接拷贝数据到主机端。该接口会根据内存特性自动调整数据存储方式。目前仅支持主机端连续内存和非连续内存的拷贝,如果将后摩设备内存数据拷贝到主机端,需要先拷贝到主机端非连续的缓存后才能拷贝到连续内存。Module::GetOutput(C++)或tcim_lite.runtime.Module.get_output(Python):获取模型输出数据时,TCIM 会自动将数据转换为主机内存格式,并拷贝到主机内存。
4.1.5.2.1. 高性能方法
如果想要更高性能,可使用以下方式先在主机端为tensor分配内存后,再调用 Tensor::CopyTo(C++)或 tcim_lite.runtime.Tensor.copy_to(Python)将tensor拷贝到主机上:
主机端为非连续存储
用户可通过下面方法最大化内存使用效率,并加速数据拷贝:
根据
TensorInfo::Stride(C++)或tcim_lite.runtime.TensorInfo.stride(Python) 获取tensor的stride信息,并根据 stride 信息计算主机端内存布局,以确保与设备端的内存布局一致。调用
Tensor::CreateHostTensor(C++)为该 tensor 在主机端分配内存。调用
Tensor::CopyTo(C++)或tcim_lite.runtime.Tensor.copy_to(Python)将tensor数据拷贝到主机端。
在此过程中,用户必须自行通过stride信息手动跳转访问数据。相比于直接调用 Tensor::CopyTo(C++)或 tcim_lite.runtime.Tensor.copy_to(Python)拷贝数据,该方法已完成数据访问的跳转,因此无需额外内存布局调整。
主机端为连续存储
用户可通过下面方法最大化内存使用效率,并加速数据拷贝:
在主机端分配内存。
调用
TensorInfo::AsContiguous(C++)或tcim_lite.runtime.TensorInfo.ascontiguous(Python)为该tensor创建一个新的TensorInfo,并设置为连续存储布局。再使用新的TensorInfo,调用Tensor::CreateHostTensor(C++)接口,在主机端为该tensor分配连续存储内存。调用
Tensor::CopyTo(C++)或tcim_lite.runtime.Tensor.copy_to(Python)将tensor数据拷贝到主机端。
相对于直接调用 Tensor::CopyTo(C++)或 tcim_lite.runtime.Tensor.copy_to(Python)拷贝数据,该方式无需使用缓存存放内存布局调整的数据。
4.1.5.3. 最佳实践
后摩设备端与主机端之间的数据拷贝速度与目标内存的布局有关,如下表所示:
拷贝方式 |
说明 |
性能 |
|---|---|---|
直接拷贝数据方式( |
如果主机端内存为连续存储,该接口会先将数据拷贝到主机端的非连续缓存,再根据目标需求从缓存重组为连续或非连续存储。 |
该方式利用中间缓存加速了数据拷贝过程,拷贝速度相较于“主机端为连续存储”方式更快,但需要额外的缓存空间,增加了内存开销。 |
高性能方法:主机端为连续存储( |
相对于“直接拷贝数据方式”,该方式无需使用缓存,从而节省了内存,但由于数据拷贝过程中需要格式转换,导致拷贝速度较慢。 |
该方式的拷贝速度较慢。 |
高性能方法:主机端为非连续存储( |
该方式下要求用户根据 stride 信息手动计算和访问数据位置,处理非连续存储的内存跳转。相比于“直接拷贝数据方式”,数据可直接在后摩设备端与主机端的非连续存储之间拷贝,省去了额外的内存布局调整。 |
该方式无需额外的内存布局调整,提供最快的数据拷贝速度,同时最大化内存使用效率。 |
4.1.6. Tensor信息
TensorInfo 类对象记录了与 tensor 相关的关键信息,包括形状、数据类型、存储布局和内存大小等。其中,存储布局用于描述当前tensor 数据在内存中的组织形式,可分为连续存储和非连续存储两种类型。
如果 TensorInfo 类对象中记录的存储布局信息为非连续存储,则不能直接将其用于设置连续存储的tensor,反之亦然。在模型推理和数据转换过程中,若存储布局不匹配,可能需要进行额外的转换操作。
TCIM 提供接口支持Tensor信息的获取及拷贝,如下图所示:
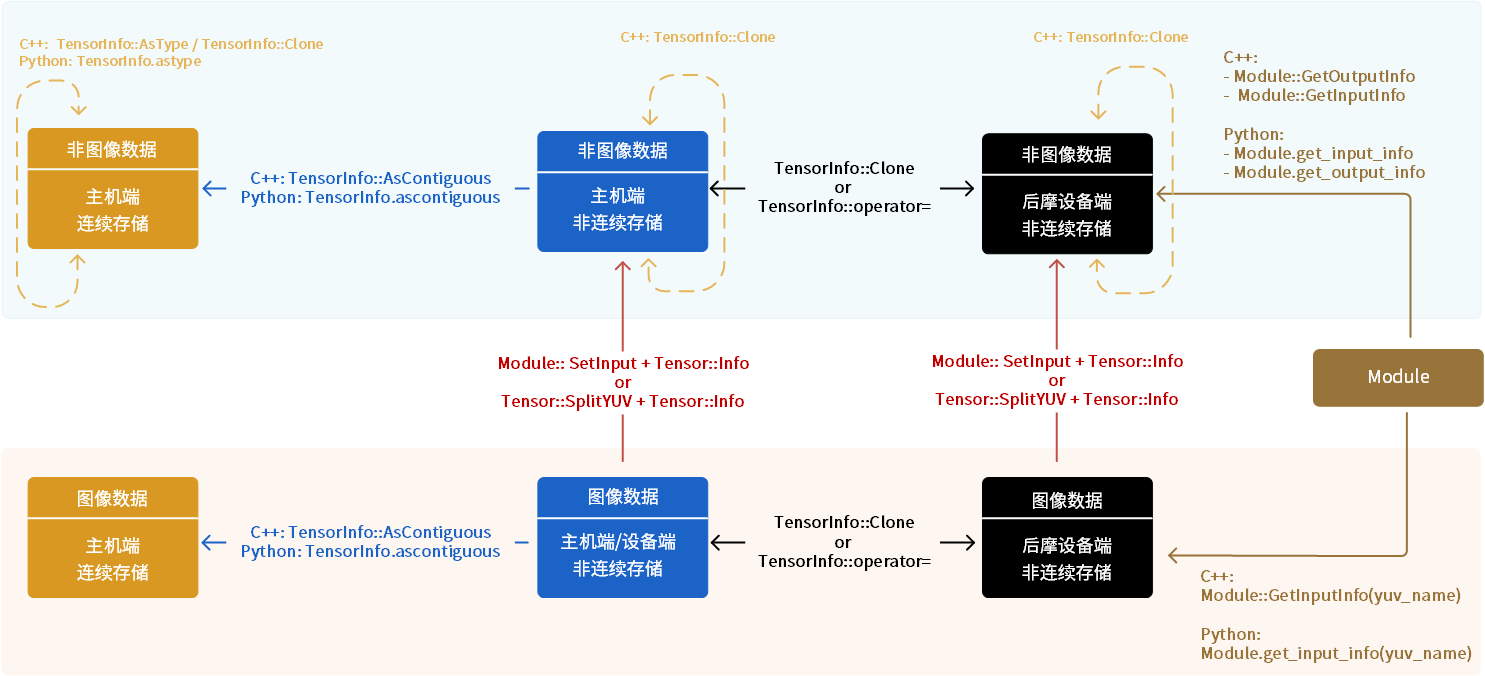
图 4.5 Tensor信息接口调用关系