2. 简介
后摩大道® M50 HMQuantool量化工具 用于对部署在 后摩漫界® M50系列产品上的模型进行解析、图优化和PTQ(Post-Training Quantization,训练后量化)。该工具支持将精度为FP16的模型转换为低精度数据类型,以满足后摩M50芯片在推理计算中的数值格式和硬件要求。量化能够有效降低运行时的内存和缓存占用,实现更低功耗和更高推理性能。
2.1. 主要功能
M50 HMQuantool量化工具基于PyTorch开发,主要功能如下:
多源模型与结构支持: 支持 ONNX、PyTorch 及 GGUF 等主流模型格式的解析,并能够灵活适配 CNN、Transformer、Mamba、RWKV 等多样化的神经网络结构,满足图像、语音、自然语言处理等多种应用场景下的模型量化需求。
一站式量化流程: 提供端到端的完整量化流程,覆盖从模型前处理、量化图构建到模型导出等阶段。工具支持在前端计算图优化基础上,灵活构建量化计算图,并导出符合 HMONNX 标准的量化模型及配套 Golden 数据。
灵活的量化格式与处理方式: 支持量化模型权重和激活数据,兼容多种量化格式,并支持离线格式转换。工具能够高效适配 M50 芯片的计算单元,有效发挥其算力优势,提升整体部署效率与运行性能,满足多样化硬件环境下的部署需求。
面向主流模型的算子兼容与对齐: 支持对 ONNX、PyTorch 等主流框架模型的解析、转换及量化,量化算子实现与 ONNX 算子及主流大语言模型中的常用算子保持深度对齐,确保良好的兼容性与准确性。
高阶量化策略与算子兼容性: 提供多种高阶PTQ量化策略,包括混合精度量化、GPTQ等,有效提升模型推理效率与精度表现。
2.2. 特性
灵活的量化格式: 结合M50芯片硬件特性,支持共享指数或共享缩放因子(scale)等机制,并提供4-bit、8-bit、16-bit等尾数精度配置,适配不同精度与性能需求。
分层中间表示架构: 工具采用分层的中间表示架构,分为前端 IR(Intermediate Representation,中间表示)、量化 IR 和导出 IR 三个阶段,逐步完成模型结构解析、量化建图和后端导出,形成从原始模型到硬件友好格式的平滑转换。
广泛模型支持: 支持计算机视觉(CV)、大语言模型(LLM)和多模态模型(VLM)等多种模型的 PTQ 量化,并广泛兼容各种常见浮点格式,如 FP16、FP32等。同时支持第三方已量化模型的导入,提升量化流程的灵活性与集成效率。
标准化 API 接口: 提供覆盖模型加载、量化配置、计算图转换及调试等全流程的标准化API,支持用户在各环节灵活调用与定制,实现量化流程的高效集成与管理。
优化加载流程: 推荐优先通过 ONNX 格式导入模型。针对基于 Transformers 库构建的大语言模型,优化模型解析和计算图构建的流程,以提升模型加载和处理效率,改善开发体验。
芯片精度模拟: 支持在无硬件环境下,精准模拟芯片的推理精度,确保量化模型的性能与实际芯片推理结果高度一致,助力开发者提前验证模型表现。
强大的算子扩展能力(即将支持): 支持自定义算子全链路接入,覆盖模型解析、量化建图到导出部署的各个阶段。通过元信息注册与量化配置接口,用户可快速集成自定义算子,无需修改核心流程,轻松实现特定算法优化和功能扩展,提升模型适配能力和部署效率。
2.3. 量化流程
后摩大道® M50 HMQuantool量化工具 流程如下图所示:
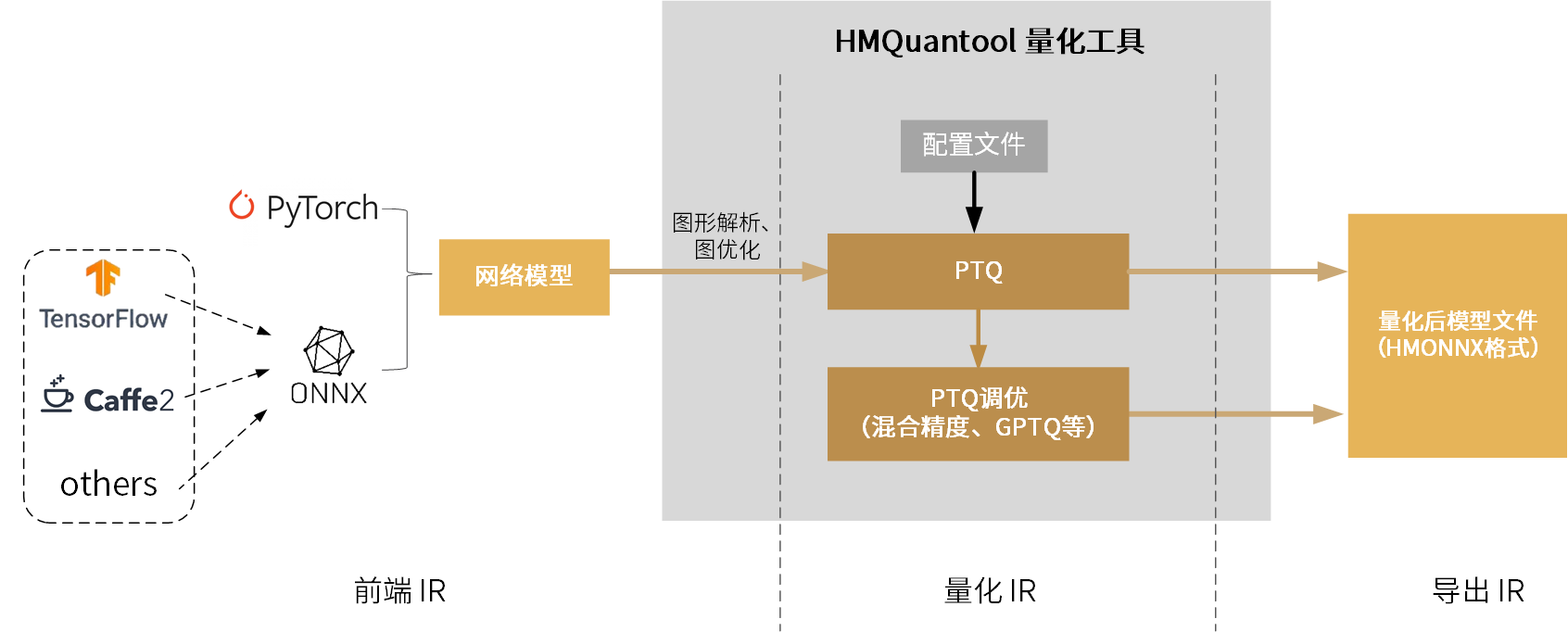
图 2.1 量化工具流程图
如上图所示,量化主要流程如下:
量化工具先对ONNX或PyTorch网络模型进行图形解析及优化。如果使用TensorFlow、Caffe等其他网络模型,需先转为ONNX模型后再进行图解析和图优化。
量化前准备。设置量化输入参数等。
PTQ量化。
模型调优。如果需要,可使用混合精度等方法对模型调优。
导出量化后HMONNX模型文件。
导出的模型可进一步通过 后摩大道® M50 TCIM(Tensor Compiler In Memory)推理加速引擎完成模型优化及高性能推理。有关TCIM详情,可参看 《TCIM用户指南》。