7. 主要接口
后摩大道® M50 HMQuantool量化工具 主要API和类介绍如下。
7.1. APIs
7.1.1. convert_onnx_to_hmonnx
xhquant.api.ptq_export_hmonnx.convert_onnx_to_hmonnx(
onnx_model_or_file: Union[str, onnx.ModelProto],
args: List[torch.Tensor],
device_type: DeviceType,
out_hmonnx_file: str,
quant_config: Optional[ConfigDict] = None,
input_names: Optional[List[str]] = None,
output_names: Optional[List[str]] = None,
mix_search: Optional[Union[dict, str]] = None,
)
量化ONNX模型,并将其转换为 HMONNX 格式,以适配后摩M50设备上推理。
参数介绍
onnx_model_or_file (Union[str, onnx.ModelProto]):输入的 ONNX 模型文件路径或已加载的模型对象。args (List[torch.Tensor]):ONNX模型的输入参数。device_type (DeviceType):目标后摩设备类型。取值为DeviceType.XH2a,即表示适配 后摩漫界® M50 系列产品的量化方法。out_hmonnx_file (str):量化后输出HMONNX的文件路径。quant_config (ConfigDict, optional):量化配置参数,由 create_quant_config 接口返回。默认为None。input_names (List[str], optional):指定量化后模型的输入节点名称列表。默认为None。output_names (List[str], optional):指定量化后模型的输出节点名称列表。默认为None。mix_search (Union[dict, str], optional):用于执行混合精度搜索。默认情况下不执行混合精度搜索,权重和激活尾数位宽由quant_type参数的取值决定。启用混合精度搜索后,量化工具会在不显著降低模型精度的前提下,自动搜索更符合硬件加速特性的精度配置,从而提升量化模型的整体精度。若需启用混合精度搜索功能,可将该参数设置为一个 YAML 配置文件路径。该文件内容格式如下所示:
topk: 0.40 weight_bits: - 4 - 8 act_bits: - 8 policy: topk task: cv_cls metric: l1 key_name: loss search_candidates: - XH2aQuantQMoeBlock - XH2aQuantQLinear - XH2aQuantQConv2d - XH2aQuantQConvTranspose2d
上述为 YAML 文件格式示例。执行混合精度搜索时,仅需配置
weight_bits、act_bits和search_candidates参数,其他参数应保持默认值。weight_bits支持取值:4、8、16。act_bits支持取值:8和16。search_candidates用于指定参与混合精度搜索的算子,默认为Linear、Moe和Conv2d算子。
用户可为参数分别设置多个候选取值。HMQuantool 量化工具将在量化过程中针对模型的不同网络层进行评估,选择最优的位宽组合,从而在保持整体模型精度的同时提升硬件执行效率。
7.1.2. create_quant_config
xhquant.api.quant_type.create_quant_config(quant_scheme: QuantScheme)
根据量化方案生成对应的量化配置参数。
参数介绍
quant_scheme (QuantScheme):量化方案配置对象,包含量化类型、目标设备等信息。详情参看 Class QuantScheme。
返回值
ConfigDict: 返回量化配置字典,该配置包含权重和激活的量化参数,供量化工具在量化时使用。
7.1.3. get_root_logger
xhquant.utils.logger.get_root_logger()
获取全局日志记录器实例,用于统一管理日志输出。
返回
返回一个自定义的日志记录器实例,用于统一管理日志输出。
7.1.4. xhquant_init
xhquant.api.xhquant_init(
log_file: Optional[str] = None,
debug: bool = False,
file_mode: str = "w"
)
初始化量化工具。
注意
模型量化前必须调用该API初始化量化工具。
参数介绍
log_file (str, optional):日志文件路径,默认值为None。debug (boolean):是否启用调试模式,默认值为False。file_mode (str): 日志文件的写入模式。取值如下:"w":创建新的日志文件(默认)。"a+":在log_file指定的日志文件中增加新日志内容,保留已有日志。
7.1.5. HMONNXGoldenInference
HMONNXGoldenInference(onnx_file: str)
模拟在后摩硬件设备上推理模型,并记录推理过程中的中间计算结果,生成参考输出数据,用于验证量化精度是否达标。
参数介绍
onnx_file (str):量化后输出HMONNX的文件路径。
7.2. Classes
7.2.1. Class DeviceType
class xhquant.common.types.DeviceType(StrEnum)
支持的后摩设备类型。
成员:
XH2a:表示适配 后摩漫界® M50 系列产品的量化方法。
7.2.2. Class LLMConverter
class LLMConverter
将 Transformers 模型量化为适用于后摩硬件的 HMONNX 格式模型。仅适用于Qwen模型。
该类定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/xh_llm/llm_converter.py 文件中。
7.2.2.1. from_pretrained
from_pretrained(
pretrained_model_path: str,
architecture: Optional[str],
convert_config: Qwen2ConvertConfig,
out_dir: str
)
从指定路径加载模型,并基于量化相关配置,将 Transformers 模型量化为适用于后摩硬件的 HMONNX 格式模型。仅适用于Qwen模型。
参数介绍
pretrained_model_path (str):原始模型路径。architecture (str, optional):指定转换时使用的模型类型,由量化工具自动推断,无需用户设置。convert_config (Qwen2ConvertConfig):量化配置参数,通过 Class Qwen2ConvertConfig 设置。out_dir (str):量化后输出HMONNX的文件路径。
该接口定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/xh_llm/llm_converter.py 文件中。
7.2.3. Class MemoryTracker
Class MemoryTracker
用于追踪设备在一段代码执行前后的内存使用情况。该类定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/utils/memory_tracker.py 文件中。
7.2.3.1. __init__
__init__(
self,
device: Union[int, str, torch.device],
name: str = None,
logger = None
)
构造函数,用于初始化 MemoryTracker 实例,指定所追踪的设备,并可选设置名称和日志记录器。
参数介绍
device (Union[int, str, torch.device]):指定要追踪的设备。name (str):用于标识该追踪器实例的名称,主要用于日志打印或调试时区分多个追踪器。logger:日志记录器对象,用于将测量结果输出到指定日志,可通过 get_root_logger 接口获取。
该接口定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/utils/memory_tracker.py 文件中。
7.2.4. Class QuantScheme
class xhquant.api.quant_type.QuantScheme(
quant_type: str = "w8a8_sefp"
target_device: DeviceType = DeviceType.XH2a
nodes: Dict[str, Union[str, Dict]] = field(default_factory=dict)
ops: Dict[str, Union[str, Dict]] = field(default_factory=dict)
input_ppc_config: Any = None
)
量化方案配置类,用于设置模型量化相关参数。
注意
模型量化前必须通过该类设置量化相关参数。
参数介绍
quant_type (str):量化策略。取值格式为wNaY_format,用于指定权重与激活值的量化尾数位宽及量化格式,其中:N:表示权重的尾数位宽,当前支持4或8。Y:表示激活值的尾数位宽,支持设置为任意 8 至 16 位之间任意整数值。format:表示所采用的量化格式,包括:sefp:共享指数采用SEFP格式表示。ssfp:共享缩放因子采用SSFP格式表示。
示例:
w8a8_sefp:量化后权重尾数位为8-bit,激活值尾数位为8-bit,量化时,缩放因子采用SEFP格式表示。该值常用于CV类模型、Stable Diffusion等量化。w4a8_ssfp:量化后权重尾数位为4-bit,激活值尾数位为8-bit,量化时,缩放因子采用SSFP格式表示。该值常用于LLM模型量化,如Qwen3-14B。
默认值为
w8a8_sefp。量化策略详情,参看 量化策略。target_device (DeviceType):目标后摩设备类型。默认值为XH2a,即表示适配 后摩漫界® M50 系列产品的量化方法。nodes (Dict[str, Union[str, Dict]]):按模型中指定节点名称,配置量化参数。默认为空字典。ops (Dict[str, Union[str, Dict]]):按模型中指定算子名称(如 Linear、MatMul 等),配置量化参数。默认为空字典。input_ppc_config (Any):模型输入预处理与数据类型配置列表,按模型输入的顺序逐一指定。该参数用于描述每个模型输入在量化与推理阶段所采用的数据类型或图像预处理配置,其取值规则如下:对于非图像类输入,使用字符串指定输入数据类型,例如
"float16"。对于图像类输入,需使用图像预处理配置 Class ResizerScheme。
例如:
["float16", "resizer_config", "resizer_config" ]。
7.2.5. Class Qwen2ConvertConfig
class Qwen2ConvertConfig:
batch_size: int = 1
context_length: int = 2048
input_sequence_length: int = 256
quant_scheme: QuantScheme = field(default_factory=QuantScheme)
quant_weight: Optional[str] = None
用于配置 Qwen模型的量化参数。
参数介绍
batch_size (int):指定模型量化时的 batch 大小。context_length (int):模型支持的最大上下文长度。该值决定了推理时可处理的最大 token 数。input_sequence_length (int):Prefill 阶段每次可处理的最大输入 token 数。quant_scheme (QuantScheme):量化方案配置对象,包含量化类型、目标设备等信息。详情参看 Class QuantScheme。quant_weight (str, optional):量化权重文件路径。
该类定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/xh_llm/models/qwen2/qwen2_convert_config.py 文件中。
7.2.6. Class Qwen2VLConvertConfig
class Qwen2VLConvertConfig:
batch_size: int = 1
context_length: int = 2048
input_sequence_length: int = 256
quant_scheme: QuantScheme = field(default_factory=QuantScheme)
visual_config: VisualConfig
用于配置 Qwen2VL多模态模型的量化参数。
参数介绍
batch_size (int):指定模型量化时的 batch 大小。context_length (int):模型支持的最大上下文长度。该值决定了推理时可处理的最大 token 数。input_sequence_length (int):Prefill 阶段每次可处理的最大输入 token 数。quant_scheme (QuantScheme):量化方案配置对象,包含量化类型、目标设备等信息。详情参看 Class QuantScheme。visual_config (VisualConfig):视觉输入相关参数,主要应用于多模态模型中图像的预处理和视觉特征提取。详情参看 Class VisualConfig。
该类定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/xh_llm/models/qwen2_vl/qwen2_vl_convert_config.py 文件中。
7.2.7. Class SD3ConvertConfig
class SD3ConvertConfig:
quant_scheme: QuantScheme = QuantScheme()
guidance_scale: float = 7.0
width: int = 512
height: int = 512
用于配置 Stable Diffusion 3 模型量化相关参数。
参数介绍
quant_scheme (QuantScheme):量化方案配置对象,包含量化类型、目标设备等信息。详情参看 Class QuantScheme。guidance_scale (float):引导系数,控制生成图像时对提示词的依赖程度。width (int):生成图像的宽度(像素),默认为 512。height (int):生成图像高度。
该类定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/xh_aigc/models/sd3/sd3_converter.py 文件中。
7.2.8. Class SD3Converter
class SD3Converter
将 Stable Diffusion 3 模型量化为适用于后摩硬件的 HMONNX 格式模型。仅适用于Stable Diffusion模型。
该类定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/xh_aigc/models/sd3/sd3_converter.py 文件中。
7.2.8.1. from_pretrained
from_pretrained(
pretrained_model_path: str,
convert_config: SD3Converter,
work_dir: str
)
从指定路径加载模型,并基于量化相关配置,将Stable Diffusion 3 模型量化为适用于后摩硬件的 HMONNX 格式模型。仅适用于Stable Diffusion模型。
参数介绍
pretrained_model_path (str):原始模型路径。convert_config (SD3Converter):量化配置参数,通过 Class SD3Converter 设置。work_dir (str):量化后输出HMONNX的文件路径。
该接口定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/xh_aigc/models/sd3/sd3_converter.py 文件中。
7.2.9. Class ResizerScheme
class xhquant.api.quant_type.ResizerScheme:
size: Any = None
align_corners: bool = True
fmt: str = "rgb"
int_trans: bool = True
crop_size: tuple = (0, 0)
crop_offset: tuple = (0, 0)
pad_size: tuple = (0, 0, 0, 0)
pad_value: int = 0
mean: List[float] = field(default_factory=lambda: [0.0, 0.0, 0.0])
std: List[float] = field(default_factory=lambda: [1.0 / 255, 1.0 / 255, 1.0 / 255])
dynamic_crop: bool = False
model_inp_fmt: str = "rgb"
图像数据预处理配置。
参数介绍
size (Any):图像预处理的目标输出尺寸,取值格式为(height, width)。height:图像预处理后输出图像的高度。width:图像预处理后输出图像的宽度。
当
dynamic_crop参数设置为True使能动态设置图像尺寸时,该参数无效。默认为 None。
align_corners (bool):插值时是否对齐角点,默认为"True"。fmt (str):原始模型图像数据格式,即图像预处理输入图像格式。支持取值包括:"rgb""yuv444""yuv420""yuv422""R8"
默认值为
"rgb"。int_trans (bool):是否启用整型转换。用于控制是否将输入图像的像素值从 [0, 255] 范围转换到 int8 表示范围。默认为True。该参数只需使用默认配置,无需用户手动设置。crop_size (tuple):设置图像裁剪尺寸,取值格式为(crop_height, crop_width)。默认值为(0, 0)。crop_height:裁剪区域的高度。crop_width:裁剪区域的宽度。
如果
width和height值为0,表示不做裁剪。当
dynamic_crop参数设置为True使能动态设置图像尺寸时,该参数无效。crop_offset (tuple):设置预处理裁剪的起始位置,取值格式为(top, left)。默认为(0, 0)。top:裁剪区域左上角纵坐标的值。值必须大于等于 0。left:裁剪区域左上角横坐标的值。值必须大于等于 0。
当
dynamic_crop参数设置为True使能动态设置图像尺寸时,该参数无效。pad_size (tuple):图像填充尺寸,取值格式为(pad_top, pad_bottom,pad_left, pad_right)。默认为(0, 0, 0, 0)。pad_top:在图像上方填充的像素数。pad_bottom:在图像下方填充的像素数。pad_left:在图像左侧填充的像素数。pad_right:在图像右侧填充的像素数。
当
dynamic_crop参数设置为True使能动态设置图像尺寸时,该参数无效。pad_value (int):图像填充的值。默认为0。当
dynamic_crop参数设置为True使能动态设置图像尺寸时,该参数无效。mean (List[float]):归一化计算参数。模型输入图像各通道均值除以255。默认值为[0.0, 0.0, 0.0]。训练时,通常对图像
![x_{uint8} \in [0, 255]](../_images/math/42ce999b294ea1310c38c15cb04fe81d3caf0972.png) 进行归一化,公式如下:
进行归一化,公式如下: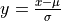
其中,
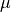 为均值,
为均值,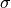 为标准差,
为标准差,![y \in [0,1]](../_images/math/a2562eb66fd7469a54a408b58700ae0df8d2dfa7.png) ,类型为FP32。
,类型为FP32。HMQuantool量化工具只接受归一化(除以255)之后的均值和标准差。例如,均值为128,则该参数值必须是(128/255)。
std (List[float]):归一化计算参数。输入图像各通道方差除以255。通常与mean参数配合使用。默认值为[1.0 / 255, 1.0 / 255, 1.0 / 255]。dynamic_crop (bool):(该功能暂不支持) 是否动态设置图像裁剪的区域。适用于图像尺寸可变的场景。取值如下:False:如果每次输入模型的图像大小是一样的,也就是每次图像裁剪的区域是固定的,则设置该参数为False。True:如果是输入模型的图像大小不一样,那么裁剪区域发生变化,则设置该参数为True。
默认为
Falsemodel_inp_fmt (str):图像预处理后的输出图像格式。取值如下:"rgb""yuv444""yuv420""yuv422""R8"
7.2.10. Class TimeProfiler
class TimeProfiler
用于测量一段代码执行时间的工具,自动记录开始和结束时间。该类定义在软件平台提供的开发样例包中 houmo-examples/hmodel/xh2/xh_model_zoo/utils/time_profiler.py 文件中。
7.2.10.1. __init__
__init__(self, name: str, logger=None)
构造函数,用于初始化 TimeProfiler 实例。
参数介绍
name (str):用于标识该追踪器实例的名称,主要用于日志打印或调试时区分多个追踪器。logger:日志记录器对象,用于将测量结果输出到指定日志,可通过 get_root_logger 接口获取。
该接口定义在软件平台提供的开发样例包中
houmo-examples/hmodel/xh2/xh_model_zoo/utils/time_profiler.py 文件中。
7.2.11. Class VisualConfig
class VisualConfig:
image_max_size: int = 1024
patch_size: int = 14
该类用于配置视觉输入相关参数,主要应用于多模态模型中图像的预处理和视觉特征提取。
参数介绍
image_max_size (int):输入图像较长边的最大尺寸(像素)。patch_size (int):图像切分成视觉token时,每个图像区域的边长(像素)。