2.3. 指令说明
模型推理性能评测工具指令如下:
Linux / Android 系统:
./tcim_perf -m <binary_model_file_name> [OPTIONS]
Windows 系统:
tcim_perf.exe -m <binary_model_file_name> [OPTIONS]
指令参数说明如下:
-m,--model:必选参数,指定用于推理的模型文件路径(.hmm)。-i,--input:可选参数,指定输入、输出和golden 数据所在文件夹。若未指定,默认为空。-o,--output:可选参数,指定性能结果文件的输出目录,默认为当前工作目录。-w,--warm_up:可选参数,指定 warm up 运行次数,用于在正式评测前预热模型,默认为 1。-b,--batch:可选参数,指定模型 batch 数,仅用于计算正确的 QPS 值,默认为 1。-l,--loops:可选参数,指定模型内部循环次数,仅用于内部测试,默认为 1。-t,--threads:可选参数,指定推理线程数,默认为 1。-d,--devices:可选参数,指定推理所使用的后摩设备数量,需与模型编译时的配置一致,默认为 1。-s,--samples:可选参数,指定测试样本数,默认为 1。-n,--name:可选参数,指定模型名称,用于匹配对应的参考输出数据。-y,--infer_only [<boolean>]:可选参数,用于指定性能统计的时间范围。取值如下:false(默认值):统计端到端完整流程的时间,包括模型推理及输入输出数据拷贝的时间。true:仅统计模型推理时间,不包括模型输入输出数据拷贝的时间。
-e, --streams:可选参数,模型推理使用的stream数量,默认为4。-p, --module_pool:可选参数,启用模型池进行推理。默认值为关闭状态。设置为true可启用该功能。-c, --modules:可选参数,指定实际加载的最大模型数量,默认值为 IPU 内核数。该参数仅在启用模型池推理时生效。-v, --interval:可选参数,按指定时间间隔(毫秒)构造输入数据并推送至推理任务队列。默认不开启,即在推理开始前将所有输入数据一次性放入任务队列。-q, --queue_length:可选参数,设置推理任务队列的最大长度。当队列中的任务数量超过该值时,程序将中止。该参数仅在配置了--interval参数时生效。-h, --help:可选参数,打印参数说明信息。
2.3.1. 使用示例
下面示例展示如何在 Linux 系统下,评测模型推理性能。在任意目录下,执行下面指令,获取 YOLOv5s推理的性能评测,默认统计端到端完整流程的时间,包括模型推理及输入输出数据拷贝的时间:
tcim_perf -m yolov5s.hmm
返回结果示例如下:
[latency] Inference avg: 3.365 ms, max: 6.331 ms, min: 2.797 ms
[latency] Input avg: 0.665 ms, max: 1.095 ms, min: 0.480 ms
[latency] Output avg: 0.247 ms, max: 0.984 ms, min: 0.110 ms
[latency] End2End avg: 4.278 ms, max: 7.316 ms, min: 3.469 ms
[Throughput] total: 110.483 ms, avg: 1.105 ms
[Throughput] qps: 905.117
上面示例结果仅供参考。
执行下面指令,获取 YOLOv5s推理的性能评测,并设置仅统计模型推理所需时间:
tcim_perf -m yolov5s.hmm -y true
返回结果示例如下:
[latency] Inference avg: 3.365 ms, max: 3.365 ms, min: 3.365 ms
[latency] Input avg: 0.000 ms, max: 0.000 ms, min: 0.000 ms
[latency] Output avg: 0.000 ms, max: 0.000 ms, min: 0.000 ms
[latency] End2End avg: 3.367 ms, max: 3.367 ms, min: 3.367 ms
[Throughput] total: 110.483 ms, avg: 110.483 ms
[Throughput] qps: 0.037
上面示例结果仅供参考。
2.4. 性能指标说明
结果参数说明:
2.4.1. 延迟时间
工具返回结果中使用 latency 字段表示延迟时间,单位为毫秒(ms),值越低越好。以下是具体的延迟指标:
Inference: 模型推理耗时,即从数据进入推理引擎到结果输出的时间。Input: 数据传输到后摩设备内存所需的时间。这部分耗时主要指将数据从主机内存移动到后摩设备内存,并设置到模型输入所需的总时间。当指令中使用-y true参数时,不统计。Output: 推理结果回传与后处理时间。这部分耗时包括将推理结果从设备内存传回主机内存,以及对结果进行解析等操作。当指令中使用-y true参数时,不统计。End2End: 默认情况下表示端到端总耗时,即Input、Inference和Output三部分耗时的总和。当指令中使用-y true参数时,仅等于Inference。
每个延迟指标都包含两个数值:
avg:多次推理或多条样本测量的平均值,反映典型耗时。max:测量中的最大耗时,用于观察峰值性能情况。min:测量中的最小耗时。
2.4.2. 吞吐量
工具返回结果中使用 Throughput 字段表示模型在一定时间内的处理能力。以下是具体的吞吐量指标:
total:模型推理总耗时,单位为毫秒(ms),用于计算吞吐量的时间基准。默认情况下包含输入、推理和输出的总耗时;当指令中使用-y true参数时,仅包含模型推理耗时。qps:吞吐量,即每秒处理的样本数。默认情况下表示端到端的吞吐量。当指令中使用-y true参数时,表示纯推理吞吐量。计算公式为: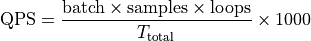
其中:
batch:模型 batch 数,默认为1。samples:测试样本数,默认为1。loops:模型内部循环次数,默认为1。total:处理这些样本所需总时间,单位为毫秒(ms)。
注:公式中的 1000 是将毫秒转换为秒,以得到每秒处理样本数。