3.3. 指令说明
模型推理性能评测工具指令如下:
Linux / Android 系统:
./llm_perf [OPTIONS]
Windows 系统:
llm_perf.exe [OPTIONS]
指令参数说明如下:
--prefill <prefill_model>:必选参数,指定prefill模型文件路径(.hmm或.hmms)。
--decode <decode_model>:必选参数,指定decode模型文件路径(.hmm或.hmms)。
--visual <vlm_model>:可选参数,用于指定VLM(Vision Large Language Model,视觉语言模型)模型文件路径。默认为LLM模型路径。
--embedding <embedding_model>:必选参数,指定embedding模型文件路径(.bin)。用户需通过
convert_embed.py工具将embedding的PT模型转换为bin文件。详情参看 Embedding模型转换。--input <prefill_token_num>:必选参数,指定prefill 阶段输入token 数。
--output <decode_token_num>:必选参数,指定 decode 阶段需要生成的 token 数,即推理输出序列的长度。
--devices <device_id>:可选参数,指定推理使用的后摩逻辑设备ID列表。
后摩逻辑设备ID表示单颗M50芯片在系统中的唯一逻辑编号;一个后摩设备中可能包含多颗M50芯片,因此可对应多个逻辑设备ID;多个后摩设备通过HM-Link(CTC)互联后,也会统一映射为多个逻辑设备 ID。
多个设备ID需使用逗号分隔,例如:
--devices 0,1。取值规则(优先级从高到低)如下:--devices参数显式指定的值。环境变量
HOUMO_VISIBLE_DEVICES取值。默认值
0(逻辑设备 0)。
注:--devices 指定多个设备(≥ 2)时,仅支持加载 .hmms格式的模型文件;.hmm格式在多设备场景下不支持。
--loop <loop_num>:可选参数,指定性能评测中重复执行同一模型的次数。默认值为1。
--batch <batch_num>:可选参数,指定模型的batch数,默认值为1。该参数取值必须与模型编译接口
build_from_hmonnx中modify_llm参数中设置的batch字段取值相同,否则将导致推理失败。--no_warm_up:可选参数,默认在正式测试前执行若干次推理过程,用于消除模型初始化和运行时冷启动带来的影响(warm up)。配置该参数后,将跳过 warm up,直接进入性能测试。
--warm_up_output <warmup_decode_token_num>: 设置warm up阶段decode模型输出的token数量,默认值为
--output <decode_token_num>参数取值。若设置--no_warm_up,则该参数值无效。--warm_up_input <warmup_prefill_token_num>: 设置warm up阶段prefill模型输出的token数量,默认值为
--input <prefill_token_num>参数取值。若设置--no_warm_up,则该参数值无效。--LazyMode: 启用 LazyMode 模式。在该模式下,模型加载过程中会延迟分配和初始化主机端缓冲区,以降低加载阶段的峰值内存占用,但可能会增加模型加载时间。默认情况下该模式关闭。
--interval <interval>: 设置后摩逻辑设备监控信息(
Device Stats)的采样间隔,包括后摩逻辑设备温度、IPU 频率、功率以及主机内存信息。单位为毫秒(ms)。默认值为 500 ms,取值范围为 100 ms ~ 60000 ms 。--skip_perf: 默认会执行性能评估。启用该参数后将跳过性能评估,仅完成模型加载,不执行模型推理。
--dump_file <filename.yaml>: 将性能数据保存到 YAML 文件。默认不导出性能数据;配置该参数后,性能数据会写入指定的 YAML 文件。
--config, -c:可选参数,通过JSON或YAML配置文件设置性能评测参数。该参数不能与其他命令行参数同时使用。若需要对多个模型进行评测,则必须使用该参数配置。详情参看 配置说明。
--help, -h:可选参数,打印工具帮助信息。
3.3.1. 配置说明
使用JSON或YAML配置文件可对多个大模型进行批量性能评测。用户只需运行一次指令即可完成全部模型的性能测试。
支持的字段如下:
ModelName:测试的大模型名称。prefill:Prefill模型文件路径(.hmm或.hmms)。decode:Decode模型文件路径(.hmm或.hmms)。embedding:Embedding模型文件路径(.bin)。input:Prefill 阶段输入token 数。output:Decode 阶段需要生成的 token 数,即推理输出序列的长度。devices:指定推理使用的后摩逻辑设备ID列表。loop:重复执行同一模型的次数。batch:模型的batch数,必须与模型编译接口build_from_hmonnx中modify_llm参数中设置的batch字段取值相同,否则将导致推理失败。no_warm_up:默认在正式测试前执行若干次推理过程,用于消除模型初始化和运行时冷启动带来的影响(warm up)。配置该参数后,将跳过 warm up,直接进入性能测试。dump_file:将性能数据保存到 YAML 文件。默认不导出性能数据;配置该参数后,性能数据会写入指定的 YAML 文件。
JSON配置文件中可以配置多个字段,分别配置不同的模型。
示例如下:
{
"Streams":[
{
"ModelName" : "deepseek_8b_256_4k_b1_1chip_2cores_v0.5.0",
"prefill" : "deepseek/deepseek_prefill.hmm",
"decode" : "deepseek/deepseek_decode.hmm",
"embedding" : "hmquant/quant_embedding.bin",
"input" : 100,
"output" : 100,
"devices" : 1,
"loop" : 2,
"batch" : 1
},
{
"ModelName": "qwen3_8b_256_8k_b4_1chip_2cores_v0.5.0",
"prefill": "qwen3/qwen3_prefill.hmm",
"decode": "qwen3/qwen3_decode.hmm",
"embedding": "qwen3/hmquant/quant_embedding.bin",
"input": 300,
"output": 400,
"devices": 1,
"loop": 1,
"batch" : 4
}
]
}
YAML配置文件中可以配置多个字段,分别配置不同的模型。
示例如下:
# Configuration for multiple LLM/VLM performance tests
Streams:
# Configuration for a single model test
- ModelName: deepseek_8b_256_4k_b1_1chip_2cores_v0.5.0
prefill: deepseek/deepseek_prefill.hmm
decode: deepseek/deepseek_decode.hmm
embedding: deepseek/hmquant/quant_embedding.bin
input: 256
output: 100
devices: 1
loop: 2
batch: 1
no_warm_up: ''
# Global output file for all performance results
# Note: This has higher priority than individual dump_file settings in Streams
dump_file: perf_result.json
3.4. 使用示例
3.4.1. 评测单个模型的推理性能
下面以Linux环境为例,在 houmo-examples-xh2/tools/bin 目录下,执行下面指令,评测Qwen3模型推理性能。需根据实际的模型路径和名称执行指令,该示例仅供参考。
./llm_perf --prefill qwen3-8b/qwen3_prefill.hmm --decode qwen3-8b/qwen3_decode.hmm --embedding qwen3-8b/hmquant/quant_embedding.bin --input 256 --output 200 --warm_up_output 100 --loop 2
返回结果示例如下:
[HostMonitorImpl] Monitoring thread has started, interval: 500ms
[2026-03-09 09:42:52.227] [tid 4651] [warning] Using TCIM_BACKEND = Xh2HalBackend as default backend
[2026-03-09 09:42:52.352] [info] DEVICE-0 Logger initialization complete, log file: ./device_logs/device_0.log
========================= Perf Settings =========================
prefill path : qwen3-8b/qwen3_prefill.hmm
decode path : qwen3-8b/qwen3_decode.hmm
embedding path : qwen3-8b/hmquant/quant_embedding.bin
input token len : 256
stop token len : 200
devices : 1
loop : 2
batch : 1
warm_up : enable
LazyMode : disable
skip_perf : disable
=================================================================
Use Devices 0
[2026-03-09 09:42:52.392] [tid 4651] [warning] Using TCIM_BACKEND = Xh2HalBackend as default backend
[2026-03-09 09:42:52.392] [tid 4651] [warning] Empty backend name, use Xh2HalBackend instead.
[2026-03-09 09:42:52.539] [info] DEVICE-1 Logger initialization complete, log file: ./device_logs/device_1.log
==============================(v)LLM Perf WarmUp: input 256, output 100===================
Device temperature: 42.048 °C
Prefill: 100% |**************************************************|
Decode: 100% |**************************************************| 100/100
==================================================================================
==============================(v)LLM Perf Loop Progress: 1/2==============================
Device temperature: 42.338 °C
Prefill: 100% |**************************************************|
Decode: 100% |**************************************************| 200/200
==================================================================================
==============================(v)LLM Perf Loop Progress: 2/2==============================
Device temperature: 44.074 °C
Prefill: 100% |**************************************************|
Decode: 100% |**************************************************| 200/200
==================================================================================
==================================================================================
Model Inference Performance Summary Report
----------------------------------------------------------------------------------
Configuration Details
----------------------------------------------------------------------------------
Batch Size: 1
Input Length per Sample: 256 tokens
Output Length per Sample: 200 tokens
----------------------------------------------------------------------------------
Inference Performance
----------------------------------------------------------------------------------
Prefill API Inference total Time: 113.08 ms | Speed: 2263.93 tokens/s
Decode API Inference total Time: 9870.75 ms | Speed: 20.26 tokens/s
Vision API Inference total Time: 0.00 ms | Speed: 0.00 images/s
----------------------------------------------------------------------------------
Overall Performance
----------------------------------------------------------------------------------
Prefill Model Load Time: 95552.91ms
Decode Model Load Time: 3530.92ms
Vision Model Load Time: 0.00ms
TTFT (Time To First Token): 114.49 ms
TPOT (Time Per Output Token): 49.97 ms/token
E2E Latency (End-to-End): 10.11 seconds
E2E TPS (Throughput): 19.78 tokens/s
----------------------------------------------------------------------------------
Memory Usage (Max Values)
----------------------------------------------------------------------------------
Physical Memory: 2.30 GB
Virtual Memory: 2.53 GB
Max Physical Memory: 3.99 GB
Max Virtual Memory: 4.66 GB
----------------------------------------------------------------------------------
Device Stats (Max Values)
----------------------------------------------------------------------------------
Device 1:
Temperature | 30.06°C(Min) | 39.63°C(Max) | 37.18°C(Avg) |
Power | 0.00 W(Min) | 0.00 W(Max) | 0.00 W(Avg) |
IPU Freq | 1400.00 Mhz(Min) | 1400.00 Mhz(Max) | 1400.00 Mhz(Avg) |
Mem Info | 24448 MB(Total) | 0 MB(Used) | 24448 MB(Avail) |
Device 0:
Temperature | 26.88°C(Min) | 42.05°C(Max) | 36.20°C(Avg) |
Power | 8.61 W(Min) | 23.87 W(Max) | 15.83 W(Avg) |
IPU Freq | 1400.00 Mhz(Min) | 1400.00 Mhz(Max) | 1400.00 Mhz(Avg) |
Mem Info | 24448 MB(Total) | 8897 MB(Used) | 15551 MB(Avail) |
----------------------------------------------------------------------------------
Prefill Stage Performance
----------------------------------------------------------------------------------
Total Time: 114.49 ms | Speed: 2236.00 tokens/s
Tokenization total Time: Skipped (No operation)
Embedding total Time: 0.32 ms
API SetInput total Time: 0.62 ms
API Inference total Time: 113.08ms | Speed: 2263.93 tokens/s
API GetOutput total Time: 0.12 ms
----------------------------------------------------------------------------------
Decode Stage Performance
----------------------------------------------------------------------------------
Total Time: 9995.00ms | Speed: 20.01 tokens/s
Tokenization total Time: Skipped (No operation)
Embedding total Time: 0.03 ms
API SetInput avg Time: 0.20 ms/token
API Inference avg Time: 49.35ms/token | Speed: 20.26 tokens/s
API GetOutput avg Time: 0.15 ms/token
==================================================================================
Every Loop Performance Result has been written to perf_dumper.log
上面示例结果仅供参考。
3.4.2. 评测多个模型的推理性能
下面以Linux环境为例,执行下面指令评测Deepseek和Qwen3模型推理性能:
./llm_perf --config config.yaml
YAML配置详情参看 配置说明。
3.5. 性能指标说明
3.5.1. 总体性能指标说明
(v)LLM Perf WarmUp :显示warm up阶段的执行进度及后摩逻辑设备运行状态。
Device temperature:当前所有后摩逻辑设备中的最高温度(°C)。Prefill:Prefill 阶段的生成进度。Decode:Decode 阶段的生成进度,表示当前已生成的 token 数量及完成百分比。
(v)LLM Perf Loop Progress :显示正式测试阶段的执行进度及后摩逻辑设备运行状态。
Loop Progress: n/N:当前执行的 loop 序号,其中 N 为总 loop 次数。Device temperature:当前所有后摩逻辑设备中的最高温度(°C)。Prefill:Prefill 阶段的生成进度条。Decode:Decode 阶段的生成进度条,显示当前推理任务的 token 生成进度。
Configuration Details :表示配置参数。
Batch Size:模型的batch数。Input Length per Sample:表示每个样本输入的 token 数量,即 Prompt 长度。Output Length per Sample:表示个样本期望生成的 token 数量,即生成长度上限。
Inference Performance :表示在完成指定 loop 次数后,模型推理阶段的性能统计,包括 Prefill、Decode 和 Vision 三个阶段的处理耗时和吞吐率。
Prefill API Inference total Time:表示Prefill 阶段的API推理总耗时。Prefill Speed:表示 Prefill 阶段的API推理吞吐率。Decode API Inference total Time:表示Decode 阶段的API推理总耗时。Decode Speed:表示Decode 阶段的API推理吞吐率。Vision API Inference total Time:表示Vision 阶段的推理耗时,用于 VL模型对输入图像执行视觉编码处理。当推理任务仅涉及 LLM 模型且不包含图像输入时,该项为 0。Vision Speed:表示图像处理吞吐率。当推理任务仅涉及 LLM 模型且不包含图像输入时,该项为 0。
Overall Performance :表示整体性能指标。
Prefill Model Load Time:Prefill 阶段所使用模型的加载耗时,表示加载模型所需的时间。Decode Model Load Time:Decode 阶段所使用模型的加载耗时,表示加载模型所需的时间。Vision Model Load Time:Vision 阶段所使用模型的加载耗时,表示加载模型所需的时间。当推理任务仅涉及 LLM 模型且不包含视觉模型时,该值为 0。TTFT (Time To First Token):表示首 token 平均延迟,衡量 Prefill 阶段每个 token 的处理时间。详情参看 TTFT。TPOT (Time Per Output Token):表示每个输出 token 的延迟(不包括首个 Token)。详情参看 TPOT。E2E Latency (End-to-End):表示从请求开始到生成全部输出 token 的端到端总耗时。详情参看 端到端延迟。E2E TPS (Throughput):表示端到端整体吞吐率,反映在当前配置下系统的综合 token 处理能力。详情参看 端到端TPS。
Memory Usage (Max Values) :表示在本轮模型测试期间,主机内存的使用量。
Physical Memory:模型加载后,主机物理内存的使用量。单位为 GB。Virtual Memory:模型加载后,主机虚拟内存的使用量。单位为 GB。Max Physical Memory:在加载模型时,主机物理内存的最大使用量。单位为 GB。Max Virtual Memory:在加载模型时,主机虚拟内存的最大使用量。单位为 GB。
Device Stats (Max Values) :表示推理过程中后摩逻辑设备的运行状态统计信息。相关日志保存在
houmo-examples-xh2/tools/llm_perf/device_logs文件夹中,每个后摩逻辑设备对应的监控日志文件为device_<id>.log。对于每个后摩逻辑设备(
Device n),统计指标说明如下:Temperature:表示后摩逻辑设备运行温度统计,分别为最小值、最大值和平均值。Power:表示推理过程中后摩逻辑设备功耗统计(单位:W),分别为最小值、最大值和平均值,用于评估能耗表现。IPU Freq:表示AI 处理器(IPU)的工作频率,分别为最小值、最大值和平均值,反映当前运行是否处于固定或动态频率模式。Mem Info:表示后摩逻辑设备内存信息,包括总容量、已使用容量和可用容量。
Prefill Stage Performance :表示在完成指定 loop 次数后,统计得到的 Prefill 阶段性能指标。
Total Time:表示Prefill 阶段的总耗时。详情参看 Prefill Total Time。Speed (tokens/s):表示Prefill 阶段的整体处理速度,按输入 token 数量计算的吞吐率。详情参看 Prefill Speed。Tokenization total Time:表示Tokenization的总耗时。Embedding total Time:表示在主机侧(CPU)将输入token转换为 embedding 的总耗时。API SetInput total Time:表示tcim runtimeModule::SetInput(C++)或Module.set_input(Python) API执行的总耗时。API Inference total Time:表示tcim runtimeModule::Run和Module::Sync(C++)或Module.run和Module.sync(Python) API执行的总耗时。API Inference Speed:表示tcim runtimeModule::Run和Module::Sync(C++)或Module.run和Module.sync(Python) API执行的速度。API GetOutput total Time:表示tcim runtimeModule::GetOutput(C++)或Module.get_output(Python) API执行的总耗时。
Decode Stage Performance :表示在完成指定 loop 次数后,统计得到的 Decode 阶段性能指标。
Total Time:表示Decode 阶段的总耗时。详情参看 Decode Total Time。Speed (tokens/s):表示Decode 阶段的整体处理速度,按输入 token 数量计算的吞吐率。详情参看 Decode Speed。Tokenization total Time:表示Tokenization的总耗时。Embedding total Time:表示在主机侧(CPU)将输入 token 转换为 embedding 的总耗时。API SetInput avg Time:表示tcim runtimeModule::SetInput(C++)或Module.set_input(Python) API执行的平均耗时。API Inference avg Time:表示tcim runtimeModule::Run和Module::Sync(C++)或Module.run和Module.sync(Python) API执行的平均耗时。API Inference Speed:表示tcim runtimeModule::Run和Module::Sync(C++)或Module.run和Module.sync(Python) API执行速度。API GetOutput avg Time:表示tcim runtimeModule::GetOutput(C++)或Module.get_output(Python) API执行的平均耗时。
Vision Stage Performance :表示在完成指定 loop 次数后,统计得到的 VLM模型性能指标。当推理任务仅涉及 LLM 模型且不包含视觉模型时,不显示该字段。
Vision Total Time:表示Vision 阶段的总耗时。Speed (tokens/s):表示Vision 阶段的整体处理速度,按输入 token 数量计算的吞吐率。Preprocessing Time:表示Preprocessing耗时。API SetInput total Time:表示tcim runtimeModule::SetInput(C++)或Module.set_input(Python) API执行的总耗时。API Inference total Time:表示tcim runtimeModule::Run和Module::Sync(C++)或Module.run和Module.sync(Python) API执行的总耗时。API Inference Speed:表示tcim runtimeModule::Run和Module::Sync(C++)或Module.run和Module.sync(Python) API执行速度。API GetOutput total Time:表示tcim runtimeModule::GetOutput(C++)或Module.get_output(Python) API执行的总耗时。
工具默认返回指定loop次数后的结果,如果查看每轮loop的性能数据,可参看 houmo-examples-xh2/tools/llm_perf/perf_dumper.log 文件。
3.5.2. Prefill Total Time
Prefill Total Time表示首token延迟,即用户输入文本后,从tokenizer开始到接收到第一个 token所需的时间,单位为ms,如下图所示:
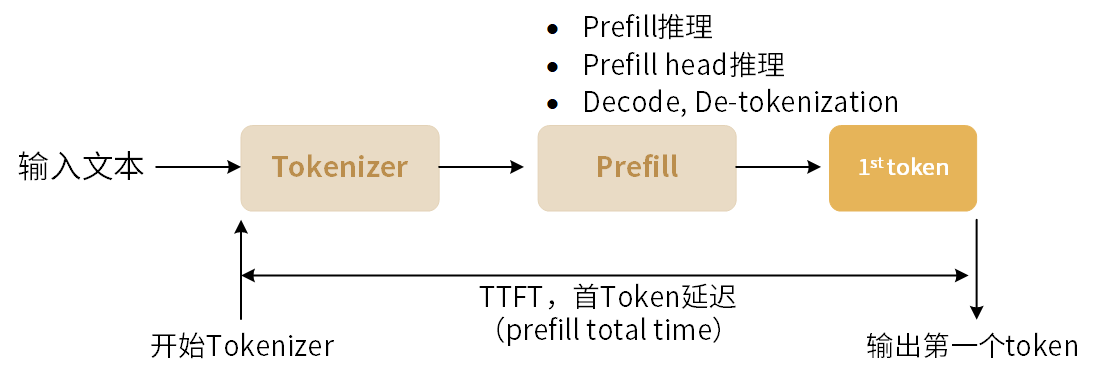
图 3.1 首Token延迟
在多batch场景下,Prefill Total Time 为所有batch首token延迟的时间总和。如果输入的上下文长度比较大,Prefill过程中会对输入tokens分段,再迭代处理每段tokens。每段输入上下文长度最大为256 tokens。因此输入上下文长度越大,首token延迟会越高。
3.5.3. Decode Total Time
生成所有输出token(不包括首个Token)的时间。在Decode阶段,从第一个token生成后,开始迭代逐个生成输出token所需的时间,单位为ms。
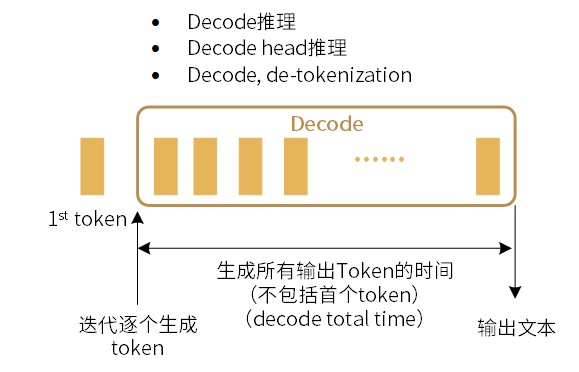
图 3.2 生成所有输出token的时间(不包括首个Token)
在多batch场景下, Decode Total Time为所有batch生成所有输出token(不包括首个token)的时间总和。
3.5.4. Prefill Speed
Prefill 阶段,处理输入 prompt时的吞吐速度,即每秒可以处理的 token 数。
计算公式如下:
prefill_speed = input_token x 1000/ prefill_time
其中,input_token 为由用户通过工具参数 --input 指定。
3.5.5. Decode Speed
Decode 阶段生成输出序列的吞吐速度,即每秒生成的 token 数。
计算公式如下:
decoding_tps = output_token x 1000 / decoding_tpot
其中,output_token 为由用户通过工具参数 --output 指定。
3.5.6. TTFT
TTFT(Time To First Token)表示首 token 平均延迟,衡量 Prefill 阶段每个 token 的处理时间,单位为ms。
计算公式如下:
prefill_ttft = prefill_time / prefill_tokens
prefill_tokens 表示Prefill阶段生成的token数量,在单batch场景下,生成的token数为1。在多batch场景下,为所有batch生成的总token数。
该指标显示用户在看到模型输出之前需要等待的时间。数值越低,意味着延迟越低,性能越好。
3.5.7. TPOT
TPOT(Time Per Output Token)表示每个输出 token 的延迟(不包括首个 Token)。
计算公式如下:
decoding_tpot = decode_time / output_token
output_token 表示Decode阶段生成的 token 数量,即为生成的总输出tokens数减去Prefill阶段生成的token数量,为由用户通过工具参数 --output 指定。在单batch场景下,为生成的总输出token数减1。在多batch场景下,为所有batch在Decode阶段生成的总token数。
该指标决定了整个推理过程需要的时间。数值越低,意味着延迟越低,性能越好。
3.5.8. 端到端延迟
端到端延迟是从发送请求到接收到最终token之间的总时间,记作 E2E Latency,单位为s。在多batch场景下,E2E Latency 为所有batch端到端延迟的时间总和。
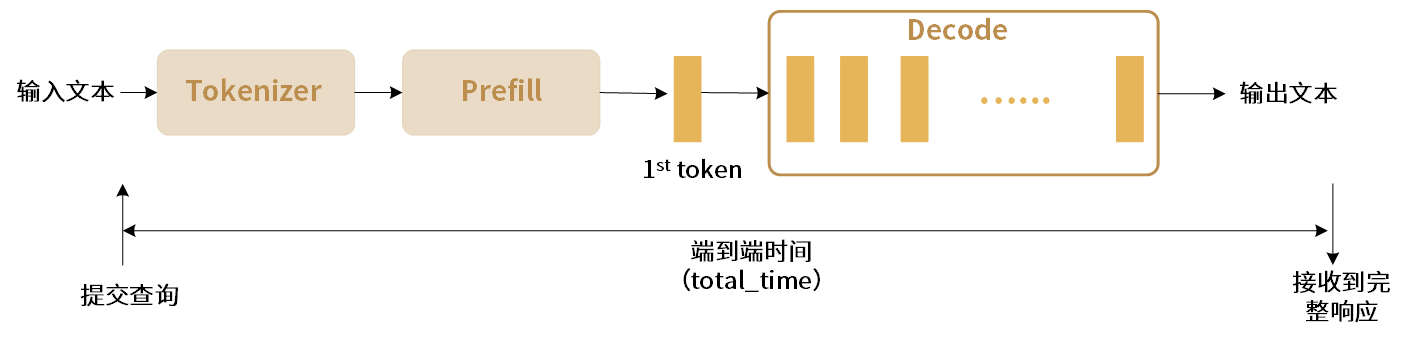
图 3.3 端到端请求延迟
3.5.9. 端到端TPS
端到端每秒生成的 tokens 数量。指模型生成文本的速度,控制着完整的响应在用户界面上显示的速度。数值越高,意味着吞吐量更大,性能更快。
公式如下:
e2e_tps = output_token / e2e_latency
其中,output_token 为由用户通过工具参数 --output 指定。
3.5.10. Embedding Time
计算在推理过程中,对输入或输出序列生成向量表示(embedding)所耗费的时间,单位为毫秒(ms)。
该指标通常用于评估模型在文本向量化阶段的性能开销,尤其在需要生成 embedding 用于下游任务或检索时。
3.6. Embedding模型转换
在运行 LLM 模型推理性能工具前,需要先将 Embedding 模型从PyTorch (PT) 格式量化后转换为 bin 格式,以便工具读取权重信息。转换脚本 convert_embed.py 与 llm_perf 工具放在同一目录下。
使用下面指令转换模型格式:
python convert_embed.py --path path/of/quant_embedding_model.pt
执行后,将在相同目录下生成对应的 bin 文件。
3.7. 常见问题解答
编译LLM 推理性能评测工具时eigen3头文件找不到
Android环境下,编译LLM 推理性能评测工具时(llm_perf ),可能出现如下错误:
/home/root/work/rk/zdyz/rk3588/sdk/houmo-examples-xh2/tools/llm_perf/utils.h:31:10: fatal error: 'eigen3/unsupported/Eigen/CXX11/Tensor' file not found 31 | #include <eigen3/unsupported/Eigen/CXX11/Tensor> | ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 1 error generated.原因:
编译环境中缺少
eigen3开发包,或CMake/include路径未正确包含eigen3头文件目录,导致编译器无法找到unsupported/Eigen/CXX11/Tensor。解决方法:
在主机端编译环境中安装
eigen3开发包。sudo apt-get install libeigen3-dev
该命令用于安装编译期所需的 eigen3 头文件,不需要在 Android 设备端执行。
检查并修改
houmo-examples-xh2/tools/llm_perf/CMakeLists.txt文件,使其与当前系统中eigen3的安装路径一致。示例如下:set(EIGEN_PATH ${CMAKE_SOURCE_DIR}/3rdparty)检查并修改
houmo-examples-xh2/tools/llm_perf/utils.h中的include路径,使其与当前系统中eigen3的安装路径一致。示例如下:#include <unsupported/Eigen/CXX11/Tensor>
清理旧编译产物后重新编译,确认
eigen3相关头文件错误已消失。
运行LLM 推理性能评测工具时返回backend不支持
运行
llm_perf时,返回下面错误信息:Error: Unsupported backend houmo DEVICE-0 Logger initialization complete, log file: ./device_logs/device_0Log
原因:
运行时需要明确当前使用的后摩设备。如果未设置 ``HOUMO_TARGET`,程序可能无法选择正确的平台配置或运行路径。
解决方法:
设置目标设备环境变量:
export HOUMO_TARGET=xh2
设置后重新运行
llm_perf,确认程序是否可以正常启动。运行LLM 推理性能评测工具时时卡死
运行
llm_perf过程中程序长时间无响应或卡死。原因:
该问题可能与输入资源格式、运行时超时设置或硬件供电能力有关。
解决方法:
请按以下方式排查:
设置较长的 API 超时时间,用于快速复现和进一步定位卡死点。
export HDPL_API_TIMEOUT=10000000
检查硬件供电是否满足运行要求,重点确认M50设备供电能力是否符合要求。
如果更换供电条件或标准验证环境后卡死消失,则优先按供电问题处理;如果仍然卡死,再继续检查输入文件、模型文件和运行时日志。
LLM 推理性能评测工具运行失败并提示 DevSet 校验失败
运行 LLM 推理性能评测工具
llm_perf时,可能返回如下错误信息:========================= Perf Settings ========================= prefill path : /hmdd/houmo-examples-xh2/apis/inferences/qwen3/qwen3_prefill.hmm decode path : /hmdd/houmo-examples-xh2/apis/inferences/qwen3/qwen3_decode.hmm embedding path : /hmdd/houmo-examples-xh2/apis/inferences/qwen3/hmquant/quant_embedding.bin devices : 2 loop: 10 batch : 1 warm_up: disable LazyMode: disable skip_perf : disable ================================================================= Use Devices 0 1 ... 'dev_manager_.impl()->DevSet().size() == 1' FAILED!
原因:
llm_perf运行时指定的 M50 芯片数量与编译后模型文件中记录的M50芯片数量不一致。错误信息
dev_manager_.impl()->DevSet().size()== 1 FAILED表示运行时设备集合数量校验失败。经确认,当前加载的prefill和decode模型文件中记录的设备数量为 1 颗 M50 芯片,而llm_perf运行时通过--devices参数指定使用 2 颗 M50 芯片,二者不一致导致校验失败。编译生成的
.hmm模型文件包含设备数量、权重切分和设备资源映射等信息。运行时指定的设备数量必须与.hmm文件中记录的设备数量保持一致。否则,运行时无法正确创建权重管理和设备映射关系,导致DevSet校验失败。解决方法:
两种解决方式:
确保运行参数与模型编译配置一致。
如果模型按 1 颗 M50 芯片编译生成,则运行
llm_perf时只指定 1 个设备,示例如下:./llm_perf --prefill qwen3-8b/qwen3_prefill.hmm --decode qwen3-8b/qwen3_decode.hmm --embedding qwen3-8b/hmquant/quant_embedding.bin --input 256 --output 200 --devices 0
更正为与实际运行设备数量匹配的模型文件。
如果需要在 2 颗 M50 芯片上运行推理,但当前
.hmm模型文件中记录的设备数量为 1 颗 M50 芯片,请更换为设备数量匹配的prefill、decode等模型文件。更换模型文件后,重新确认
--devices参数与模型文件中记录的设备数量一致。
Android环境下运行LLM 推理性能评测工具提示libhal_xh2a.so未找到
在Android环境中运行
llm_perf时,可能返回如下错误信息:CANNOT LINK EXECUTABLE "llm_perf": library "libhal_xh2a.so" not found: needed by main executable
原因:
工具运行时依赖
libhal_xh2a.so动态库。如果运行环境未配置正确的后摩驱动库路径,系统动态链接器无法找到该库,导致程序启动失败。解决方法:
设置
HOUMO_SDK_PATH环境变量,使其指向主机端后摩驱动库所在目录。libhal_xh2a.so通常位于驱动安装包的以下目录中:houmo-drv-xh2_<release>_android_$arch/houmo-drv-xh2/hal/lib
可按实际安装路径设置环境变量,例如:
export HOUMO_SDK_PATH=/path/to/houmo-drv-xh2_<release>_android_$arch/houmo-drv-xh2/hal/lib
设置完成后,重新运行
llm_perf。