3.2. LLM编译
TCIM支持部署LLM(Large Language Model,大语言模型)到后摩硬件设备上,包括Qwen3.5、Qwen3.6等模型。
Qwen模型包括以下部分:
Prefill模型:用来计算所有输入token,生成对应的KV Cache,并预测第一个输出token。
Decode模型:迭代的将预测输出的token送入模型。每轮将上一次预测出的token的embedding输入模型,复用并更新已有的KV Cache、recurrent cache,然后根据本轮Decode输出预测下一个token。
下面以Qwen模型为例,介绍如何在单batch场景下,编译Qwen模型。示例展示关键步骤代码,仅供参考,不可以直接拷贝运行。用户可通过下面方式获取样例代码:
(仅限Linux系统)开发样例包中
houmo-examples_<release>/houmo-examples-xh2/models/llm目录下。
3.2.1. 编译模型步骤
Qwen模型编译主要流程如下:
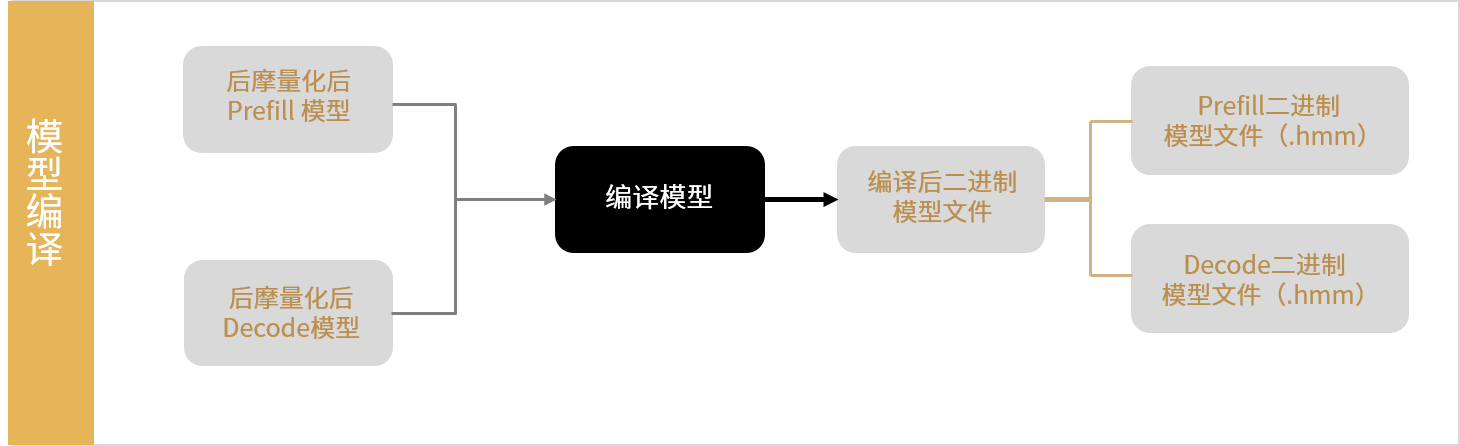
图 3.1 Qwen模型编译主要流程
调用 build_from_hmonnx Python API分别编译Prefill和Decode模型。编译后分别生成 Prefill二进制模型文件(.hmm或.hmms)和 Decode二进制模型文件(.hmm或.hmms)。TCIM仅支持在Linux X86_64环境下编译模型。
警告
由于Qwen网络模型较大,编译主机必须具备至少64GB的可用内存,否则可能因内存不足导致OOM(Out of Memory)错误,或者模型编译被终止。
示例如下:
# Retrieve the target Houmo device
HOUMO_TARGET = os.getenv("HOUMO_TARGET")
# Retrieve the number of IPU cores used for inference
HOUMO_CORE_NUM = os.getenv("HOUMO_CORE_NUM", 2)
# Build models
def build(model_name, model_dir, model_path, output_dir, profile, ncore, ndevice, context_length, batch=None,):
import tcim
kwargs = {}
if HOUMO_TARGET == "xh2":
kwargs["modify_llm"] = {}
kwargs["enable_xh2_stable_output"] = True
if ndevice:
kwargs["ndevice"] = ndevice
if batch:
kwargs["modify_llm"]["batch"] = batch
if context_length:
kwargs["modify_llm"]["context_length"] = context_length
start = time.time()
decode_model = os.path.join(model_dir, model_path)
tcim.build_from_hmonnx(
decode_model,
weights=os.path.join(model_dir, "weight.npy"),
output_name=model_name,
ncore=ncore,
target=HOUMO_TARGET,
output_dir=output_dir,
work_dir=os.path.join(output_dir, "tcim"),
llm_opt=True,
**kwargs,
)
profile["build"] = time.time() - start
print(f'{model_name} build completed in {profile["build"]:.3f} s.', flush=True)
if __name__ == '__main__':
model_dir = os.path.join('output', HOUMO_TARGET, 'hmquant')
model_name = "qwen3"
output_dir = os.path.join('output', HOUMO_TARGET)
ncore = HOUMO_CORE_NUM
batch = 1
ndevice = 1
context_length = 2048
profile = {}
# Set the Prefill model path
model_path = f"prefill/hmquant_{model_name}_with_act.onnx"
# Build Prefill model
build(f"{model_name}_prefill",, model_dir, model_path, output_dir, profile, ncore, ndevice, context_length,)
# Set the Decode model path
model_path = f"decoder/hmquant_{model_name}_with_act.onnx"
# Build Decode model
build(f"{model_name}_decode", model_dir, model_path, output_dir, profile, ncore, ndevice, context_length, batch,)
# (Optional) Build MTP Prefill model
model_path = f"draft_prefill/hmquant_{model_name}_with_act.onnx"
build(f"{model_name}_prefill_mtp", model_dir, model_path, output_dir, profile, ncore, ndevice, context_length, batch,)
# (Optional) Build MTP Decode model
model_path = f"draft_decode/hmquant_{model_name}_with_act.onnx"
build(f"{model_name}_decode_mtp", model_dir, model_path, output_dir, profile, ncore, ndevice, context_length, batch,)
根据上面示例,模型编译后生成 qwen3.5_prefill.hmm 和 qwen3.5_decode.hmm 二进制模型文件。如果使用使用MTP功能,量化会额外生成 draft_prefill 和 draft_decode 两个MTP draft模型,模型编译生成MTP模型 qwen3.5_prefill_mtp.hmm、qwen3.5_decode_mtp.hmm。
TCIM API详情,参看 《TCIM开发者手册》。