2.3. 指令说明
在应用开发示例包 houmo-examples-xh2/tools/computing_perf 目录下,通过执行 Python 脚本启动算力测试工具:
python3 computing_perf.py [OPTIONS]
指令参数说明如下:
--work-dir <output>:指定模型编译和推理过程中,中间计算结果的存放路径。默认为当前路径下的output目录。--device-id <id>:指定进行算力测试的目标芯片的逻辑设备 ID。默认值为0。可通过后摩SMI工具查询可用的设备 ID,详情参看 《SMI工具使用指南》。--skip-build:Flag 参数,若设置,则跳过 ONNX 模型的编译步骤,仅执行模型推理。默认情况下会执行模型编译。--sample-num <sample_num>:指定算力测试过程中,用于计算有效算力所使用的样本总数量。默认值为 512。--compute-mode <mode>:指定算力测试的数据精度模式。<mode>取值如下:注意
目标设备 M50 芯片有多个硬件修订版本。int8 模式仅在 V2 版本芯片上支持,bfp16 模式在 V1 和 V2 版本芯片上均支持。
int8:以 INT8 精度进行算力测试,结果以 TOPS@INT8 表示。bfp16:以 bFP16 精度进行算力测试,结果以 TFLOPS@bFP16 表示。
2.3.1. 使用示例
在 houmo-examples-xh2/tools/computing_perf 目录下,执行下面指令,指定设备 ID 和样本数量,并跳过模型编译:
python3 computing_perf.py --device-id 0 --sample-num 1024 --skip-build --compute-mode bfp16
2.4. 性能指标与结果解析
返回结果示例如下:
Model run successfully on device 0, elapsed time: 11.86 seconds.
============================================================
Performance Test Summary
============================================================
Model Parameter | Value
------------------------------------------------------------
Number of Conv2d Layers | 64
Batch Size | 1
Input Channels | 256
Output Channels | 256
Feature Map Size | [64, 64]
Kernel Shape | [3, 3]
------------------------------------------------------------
Computing amount | 0.3092 TFLOPs/sample
Test time | 1.9529 seconds
PERFORMANCE | 81.07 TFLOPS@bFP16
============================================================
结果参数说明:
Number of Conv2d Layers: 用于构建测试模型的 Conv2d 算子的总层数。
Batch Size: 模型单次推理的样本batch大小。
Input Channels: 卷积层输入特征图的通道数量。
Output Channels: 卷积层输出特征图的通道数量。
Feature Map Size: 卷积层输入特征图的高度和宽度。
Kernel Shape: 卷积核的高度和宽度。
Computing amount: 基于上述模型参数,计算得出的单样本推理所需的总理论浮点运算次数。
Test time: 完成所有预设样本数量推理任务所消耗的总时间。
PERFORMANCE: 实际有效算力。
2.4.1. 核心指标计算公式
实际有效算力是衡量芯片端到端综合性能的关键指标。它的计算基于吞吐量模型:
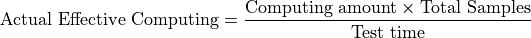
其中:
Computing amount:表示单样本推理所需的总理论浮点运算次数。Test time:表示完成所有预设样本数量推理任务所消耗的总时间。Total Samples:总样本数,默认为512。
2.5. 常见错误解析
芯片算力基准测试失败并提示IPU同步超时
运行芯片算力基准测试工具时,如果返回下面错误信息:
Process Process-4: [2026-04-09 13:52:17.828] [tid 45] [error] src/backend/tcim_backend_xh2a_hal.cc:732:YieldStream: 'info->SyncDone() ' values: 12 !=0 FAILED! [2026-04-09 13:52:17.828] [tid 45] [error] [Stream] [0xc8ae540] Model:xh2_conv DevID:0 SyncYieldErr:12 Stream:0xc8b7170 [2026-04-09 13:52:17.828] [tid 45] [error] src/tcim_stream_impl.cc:107:SyncYield: 'ret != tcim::Status::ERR_FATAL' FAILED! [Status: 0] [2026-04-09 13:52:17.828] [tid 45] [error] src/tcim_module_impl.cc:533:Sync: 'stream_.impl()->Sync() ' values: 12 !=0 FAILED! Process Process-1: [2026-04-09 13:52:17.830] [tid 62] [error] Executor error ret: 7 [2026-04-09 13:52:17.830] [tid 45] [error] SyncDone: Failed = 7 xh2a_ipu_sync_group failed! ret:110 result:0 group_id:0 timeout_us:100000000
解决方法:
执行下面步骤复位IPU核:
使用后摩SMI工具复位指定后摩芯片的IPU核:
sudo hm_smi -rd <device_id>
其中
<device_id>应替换为后摩逻辑设备ID,即单颗M50芯片在系统中的逻辑编号。设备复位完成之后,建议先运行小样本任务验证硬件连通性:
python3 computing_perf.py --device-id 0 --sample-num 4 --skip-build