6.6.3. 性能评测指标
了解模型的性能对于优化其效率和效果至关重要。ModelZoo Qwen模型开发样例提供模型推理性能数据的展示,帮助用户了解当前模型推理性能。
6.6.3.1. 背景知识
Token
Token是LLM中特有的概念,也是LLM推理性能的核心指标。它是LLM用来拆分、解析和处理自然语言的基本单位。每个LLM都有一个从数据中训练得到的专属 tokenizer,用于高效地表示输入文本。每个 token 约为1.5个中文字符。
上下文长度
上下文长度是指LLM在一次处理过程中能够理解和生成的文本的最大长度。每个LLM都有一个最大上下文长度,用于表示模型输入、输出最大token数。
Batch
Batch是指能够被推理引擎同时处理的请求(session)数量。最大batch数是指推理引擎能够同时处理的最大请求数量。如果用户并发请求数量超过最大batch数,那么部分请求将需要排队等待处理。排队等待的时间未计入性能评测的计算中。
6.6.3.2. 评测指标
性能评测指标如下:
TTFT (Time to First Token)
首token延迟,即从输入到输出第一个token的延迟。该指标显示用户在看到模型输出之前需要等待的时间。数值越低,意味着延迟越低,性能越好。
TPOT (Time per Output Token)
每个输出token的延迟(不包括首个Token)。该指标决定了整个推理过程需要的时间。数值越低,意味着延迟越低,性能越好。
TPS (Tokens Per Second)
每秒生成的tokens数量。指模型生成文本的速度,控制着完整的响应在用户界面上显示的速度。数值越高,意味着吞吐量更大,性能更快。
端到端延迟 (end2end latency)
从发送请求到接收到最终token的总时间。数值越低,意味着延迟越低,性能越好。
Qwen模型样例性能评测示例如下:
total: 460 tokens, cost 54.093 s
prefill time: 312.272 ms, 3.20 tokens/s
decode average time: 117.156 ms, 8.54 tokens/s
end2end average time: 117.594 ms, 8.50 tokens/s
其中:
total:从输入文本到输出文本的总输出token数(460 tokens)及总时间(54.093 s)。prefill time:Prefill阶段的性能指标,即生成第一个token的TTFT(312.272 ms)和TPS(3.20 tokens/s)。decode average time:Decode阶段的性能指标,即生成每个输出token(不包括首个Token)的TPOT(117.156 ms)和TPS(8.54 tokens/s)。end2end average time:端到端从输入文本到输出文本,每个输出token的TPOT(117.594 ms)和TPS(8.50 tokens/s)。
6.6.3.3. 首Token延迟及TPS
首token延迟的计算是在Prefill阶段,用户输入文本后,从tokenizer开始到接收到第一个 token所需的时间,记作 prefill_time,单位为s,如下图所示:
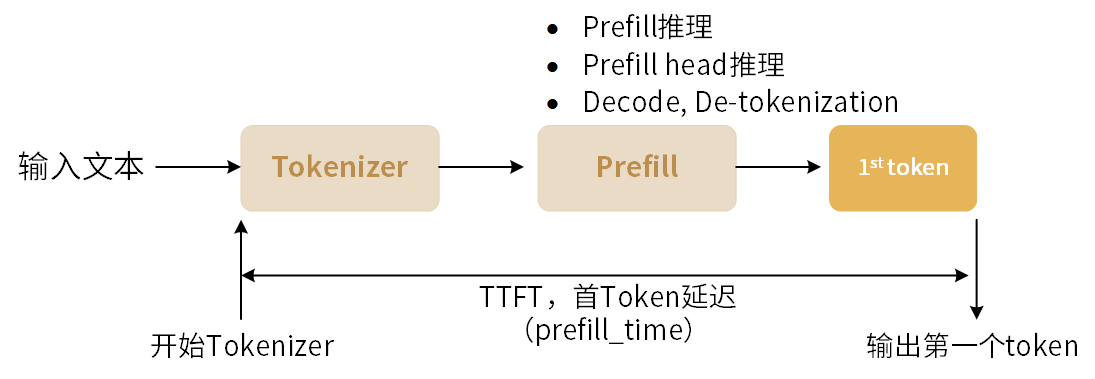
图 6.1 首Token延迟
在多batch场景下,prefill_time 为所有batch首token延迟的时间总和。如果输入的上下文长度比较大,Prefill过程中会对输入tokens分段,再迭代处理每段tokens。每段输入上下文长度最大为256 tokens。因此输入上下文长度越大,首token延迟会越高。
TTFT(单位为ms)
prefill_ttft = prefill_time * 1000 / prefill_tokens
prefill_tokens 表示Prefill阶段生成的token数量,在单batch场景下,生成的token数为1。在多batch场景下,为所有batch生成的总token数。
Prefill阶段TPS(单位为tokens/s)
prefill_tps = 1000 / prefill_ttft
6.6.3.4. 每个输出token的延迟及TPS
生成所有输出token的时间(不包括首个Token)是在Decode阶段,从第一个token生成后,开始迭代逐个生成输出token所需的时间,记作 decoding_time,单位为s。
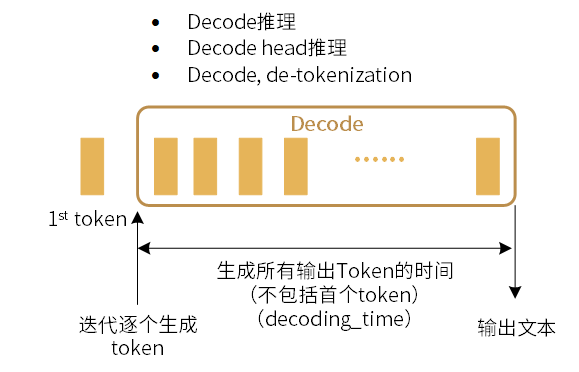
图 6.2 生成所有输出token的时间(不包括首个Token)
在多batch场景下,decoding_time 为所有batch生成所有输出token(不包括首个token)的时间总和。
TPOT(单位为ms)
decoding_tpot = decoding_time * 1000 / decoding_tokens
decoding_tokens 表示Decode阶段生成的 token 数量,即为生成的总输出tokens数减去Prefill阶段生成的token数量。在单batch场景下,为生成的总输出token数减1。在多batch场景下,为所有batch在Decode阶段生成的总token数。
Decode阶段TPS(单位为tokens/s)
decoding_tps = 1000 / decoding_tpot
6.6.3.5. 端到端延迟及TPS
端到端延迟是从发送请求到接收到最终token之间的时间差,记作 total_time,单位为s。在多batch场景下,total_time 为所有batch端到端延迟的时间总和。
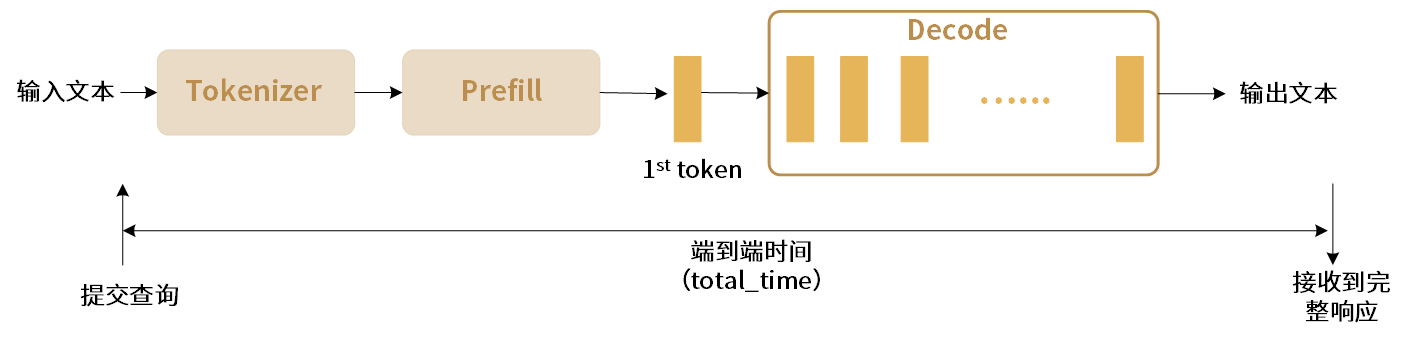
图 6.3 端到端请求延迟
端到端每个输出token的延迟(单位为ms)
e2e_tpot = total_time * 1000 / tokens
tokens 为生成的总输出tokens数。在多batch场景下,为所有batch生成输出tokens数的和。
端到端TPS(单位为tokens/s)
e2e_tps = 1000 / e2e_tpot